Vulkan 튜토리얼: 파이프라인 배리어를 이용하여 이미지 레이아웃 변경하기
이번 튜토리얼에서는 어떻게 GPU 파이프라인에 맞게 이미지의 레이아웃을 변경하고, 적절히 변경한 레이아웃을 바탕으로 이미지를 호스트 단으로 복사하여 저장할 것입니다.
GPU가 상당히 파이프라인화(pipelined)된 기기임은 잘 알려진 사실입니다. 이 말인 즉슨, 큐에 제출된 어떤 커맨드는 다음과 같은 각 파이프라인의 스테이지를 거쳐가며 필요한 부분에서 동작한다는 뜻입니다.
TOP_OF_PIPE_BITDRAW_INDIRECT_BITVERTEX_INPUT_BITVERTEX_SHADER_BITTESSELLATION_CONTROL_SHADER_BITTESSELLATION_EVALUATION_SHADER_BITGEOMETRY_SHADER_BITFRAGMENT_SHADER_BITEARLY_FRAGMENT_TESTS_BITLATE_FRAGMENT_TESTS_BITCOLOR_ATTACHMENT_OUTPUT_BITTRANSFER_BITCOMPUTE_SHADER_BITBOTTOM_OF_PIPE_BIT
커맨드는 TOP_OF_PIPE_BIT에서부터 시작하고, 중간 파이프라인을 거치며 필요한 명령을 실행하고, BOTTOM_OF_PIPE_BIT에서 끝나게 됩니다. 이 모든 단계를 반드시 거치는 것은 아니지만, 어쨌든 이러한 순서로 실행됨을 예측할 수 있습니다.
“커맨드 버퍼”가 아닌 “커맨드”라는 용어를 썼음을 유의하세요. 한 커맨드 버퍼는 여러개의 커맨드로 구분될 수 있고, 따라서 몇 번의 파이프라인을 거칠 수 있습니다.
또한, Vulkan의 커맨드 버퍼에 기록된 커맨드는 그 실행 흐름이 순차적이지 않습니다. 순차적이지 않다는 말은 커맨드의 시작은 순차적이나, 어떤 커맨드 뒤에 기록된 커맨드는 꼭 그 앞의 커맨드가 끝날 때까지 실행이 지연되지 않는다는 것입니다. 예를 들어, 앞서 버퍼 입출력 소주제의 코드를 살펴봅시다.
1
2
3
4
commandBuffer.bindPipeline(vk::PipelineBindPoint::eCompute, *computePipeline);
commandBuffer.bindDescriptorSets(vk::PipelineBindPoint::eCompute, *pipelineLayout, 0, descriptorSet, {});
commandBuffer.dispatch(1024 / 256, 1, 1);
commandBuffer.dispatch(1024 / 256, 1, 1); // New command!
예시를 위해 파이프라인 디스패치 밑에 디스패치를 한 번 더 실행했습니다. 두 번째 디스패치는 첫 번째 디스패치가 시작된 후 시작하지만, 이 말은 첫 번째 디스패치가 끝날때까지 기다렸다가 시작한다는 뜻이 아닌, 병렬적으로 실행될 수 있다는 뜻입니다. 그렇기에 만일 처음 커맨드가 GPU의 전체 자원을 점유하지 않는 경우, 두 번째 디스패치를 같이 실행하며 성능의 이점을 꾀할 수 있습니다.
이러한 병렬 실행은 성능 면에서 이점을 갖지만, 간혹 우리가 원하는 결과를 얻지 못하게 되는 요인이 되기도 합니다. 예를 들어, 어떤 커맨드 버퍼에 “버퍼에 데이터를 기록하는 커맨드”와 “기록된 커맨드를 읽어 연산을 수행하는 커맨드”가 순차적으로 기록되어 있다고 가정해봅시다. 만일 두 커맨드가 병렬적으로 실행된다면, 두 번째 커맨드는 첫 번째 커맨드가 끝나기 전에 실행되어, 잘못된 결과를 가져올 수 있습니다1.
따라서 이러한 상황을 막기 위해, 어떤 커맨드 간에는 서로의 실행 순서가 규정되어야 합니다. 실행 순서를 규정하는 방법은 파이프라인 배리어/세마포어/펜스/이벤트(event) 등이 있으며, 이번 튜토리얼은 그 중에서도 파이프라인 배리어에 대해 알아볼 것입니다.
파이프라인 배리어
파이프라인 배리어는 같은 커맨드 버퍼 내 커맨드 간의 동기화 배리어를 설정할 수 있게 합니다. 파이프라인 배리어는 다음 두 가지의 배리어를 설정할 수 있게 합니다:
- 실행 배리어(execution barrier): 이는 커맨드 버퍼 내 인접한 두 커맨드의 실행 순서를 설정하게 할 수 있습니다. 두 인접한 커맨드를 A, B라 할 때, A가 파이프라인의 어떤 스테이지(이를
srcStageMask인수로 전달합니다)를 끝마치기 전까지 B가 어떤 스테이지(이를dstStageMask인수로 전달합니다)에서 실행되는 것을 지연시킬 수 있습니다. 이 때srcStageMask는 논리적으로 그보다 앞선 스테이지까지 확장되며,dstStageMask역시 논리적으로 그보다 뒤에 있는 스테이지까지 확장됩니다. 따라서, 그 결과로 B가dstStageMask에서 읽는 결과물은 A가srcStageMask에서 쓴 결과물을 완전히 읽을 수 있게 합니다. - 메모리 배리어(memory barrier): 이는 실행 순서 배리어와는 약간 다른데, Vulkan 또한 CPU와 마찬가지로 어떤 데이터의 쓰기 연산을 바로 VRAM에 적용하는 것이 아닌, 레지스터-L1 캐시-L2 캐시-메모리 순으로 순차적 데이터 이동을 거칩니다. 그렇기에 어떤 GPU 코어에서 캐시에 쓴 연산이 메모리에 반영되지 않아 다른 코어에서 분명히 시간적으로 늦게 해당 메모리를 읽었음에도, 그 결과값이 반영되지 않을 수 있습니다. 메모리 배리어를 이용하면 배리어 이전 커맨드의 캐시를 램으로 flush하여 이후 커맨드가 이를 읽을 수 있게 합니다. 다만, flush는 비싼 작업이기 때문에 Vulkan은 전후 커맨드의 어느 스테이지에서 이 과정을 수행할 지 조정할 수 있게 합니다.
srcAccessMask는 이전 커맨드의 어떤 접근 마스크 (access mask)부터 flush를 실행할 수 있는지,dstAccessMask는 이후 커맨드의 어느 접근 마스크 전까지 flush를 끝내야 하는지 설정합니다. 메모리 배리어는 다음 세 가지를 지정할 수 있습니다.- 전역 메모리 배리어(global memory barrier): 전역적으로 설정되는 메모리 배리어입니다.
- 버퍼 메모리 배리어(buffer memory barrier): 명시된 버퍼에 대해서만 작용하는 메모리 배리어입니다.
- 이미지 메모리 배리어(image memory barrier): 명시된 이미지에 대해서만 작용하는 메모리 배리어입니다. 이 배리어는 이미지의 레이아웃을 변경하는데 사용할 수 있습니다.
굉장히 복잡합니다. 마찬가지로 이 모든 것을 바로 이해할 필요는 없습니다. 그 대신, 다음을 기억하세요.
- 대개 이미지 레이아웃을 변경하는 경우 이미지 메모리 배리어를, 그 외의 경우 실행 배리어를 많이 사용하는 편입니다.
- 특정 리소스에 대해서만 메모리 배리어를 실행해야 하는 경우 버퍼 메모리 배리어/이미지 메모리 배리어를 사용하는 것이 전역 메모리 배리어보다 더 fine-grained한 조작이 가능하므로, GPU에 더 많은 최적화의 이점을 제공합니다.
- 앞선 커맨드의
srcStageMask가 끝나기 전까지 후속 커맨드의dstStageMask가 기다려야 하기 때문에, 가능하다면srcStageMask파이프라인 스테이지의 높은 곳에 (TOP_OF_PIPE_BIT에 가까울수록),dstStageMask파이프라인 스테이지의 낮은 곳에 (BOTTOM_OF_PIPE_BIT에 가까울수록) 성능 면에서 유리합니다.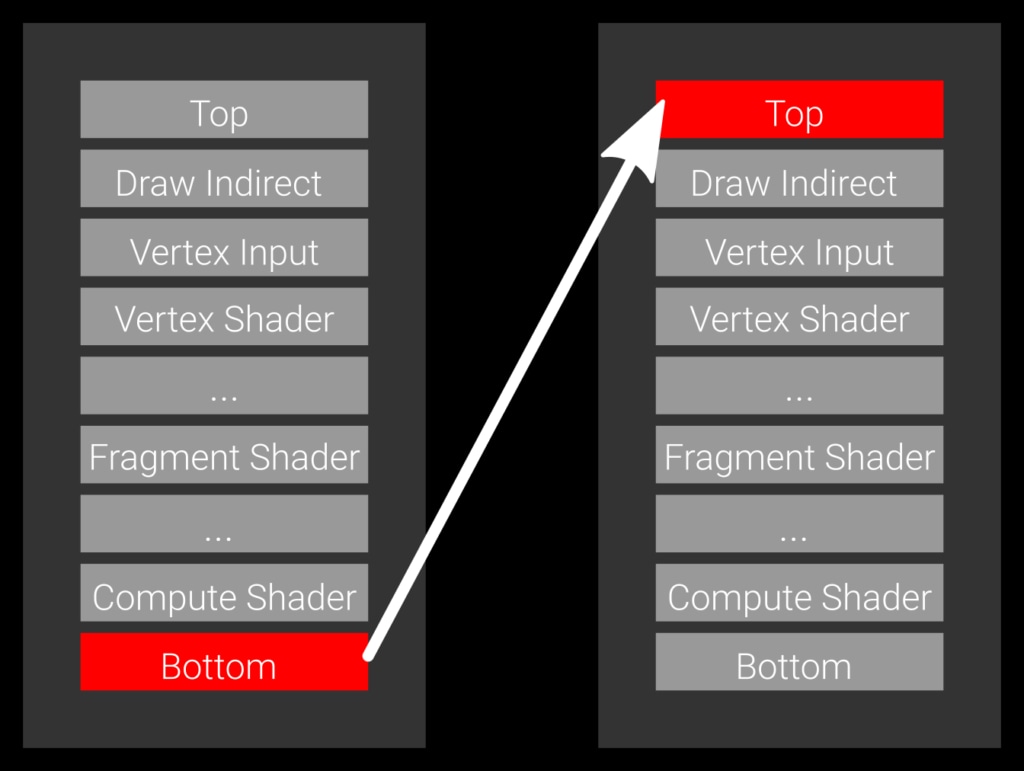 최악의 배리어. 전 커맨드가 파이프라인을 모두 통과하기 전까지 후속 커맨드는 시작하지도 못합니다. 반대로 위와 같은 배리어는 두 커맨드를 완전히 순차적으로 실행하게끔 하므로, GPU의 어떤 비순차적 처리의 이점도 얻을 수 없습니다.
최악의 배리어. 전 커맨드가 파이프라인을 모두 통과하기 전까지 후속 커맨드는 시작하지도 못합니다. 반대로 위와 같은 배리어는 두 커맨드를 완전히 순차적으로 실행하게끔 하므로, GPU의 어떤 비순차적 처리의 이점도 얻을 수 없습니다.
이제 실제로 파이프라인 배리어를 이용하여 이미지의 레이아웃을 변경해보도록 하겠습니다.
이미지 레이아웃 변경하기
computePipeline으로 디스패치한 커맨드는 위 파이프라인 스테이지 중 COMPUTE_SHADER_BIT에서 작용합니다. 그 중에서도 이미지는 적어도 해당 셰이더에서 쓰기 연산이 이루어지기 전 GENERAL 레이아웃으로 바뀌어야 합니다. 따라서, 우리는 레이아웃 변경 배리어를 다음과 같이 설정할 수 있습니다.
srcStageMask:eTopOfPipe(앞선 커맨드가 존재하지 않으므로)dstStageMask:eCompute(레이아웃 변경은 컴퓨트 스테이지 전까지 이루어져야 함)srcAccessMask:eNone(앞선 커맨드에서 어떤 접근도 발생하지 않음)dstAccessMask:eShaderWrite(레이아웃 변경은 셰이더에서 쓰기 연산이 발생하지 전까지 이루어져야 함)
이를 바탕으로, 커맨드 버퍼에 파이프라인 배리어를 기록해보겠습니다.
Subject: [PATCH] Change image layout to GENERAL before compute pipeline dispatch
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -241,11 +241,27 @@
1,
}).front();
- // Record commands that invoke computePipeline.
commandBuffer.begin({ vk::CommandBufferUsageFlagBits::eOneTimeSubmit });
+
+ // Change image layout to GENERAL.
+ {
+ const vk::ImageMemoryBarrier barrier {
+ {}, vk::AccessFlagBits::eShaderWrite,
+ {}, vk::ImageLayout::eGeneral,
+ {}, {},
+ *image,
+ vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
+ };
+ commandBuffer.pipelineBarrier(
+ vk::PipelineStageFlagBits::eTopOfPipe, vk::PipelineStageFlagBits::eComputeShader,
+ {}, {}, {}, barrier);
+ }
+
+ // Invoke computePipeline.
commandBuffer.bindPipeline(vk::PipelineBindPoint::eCompute, *computePipeline);
commandBuffer.bindDescriptorSets(vk::PipelineBindPoint::eCompute, *pipelineLayout, 0, descriptorSet, {});
commandBuffer.dispatch(512 / 16, 512 / 16, 1);
+
commandBuffer.end();
// Submit commandBuffer to computeQueue and wait for it to finish.
먼저 이미지 메모리 배리어를 적용하기 위해 해당 변수를 선언했습니다. 1번째 {}는 vk::AccessFlagBits의 기본값이 eNone이므로 기본값으로 명시했고, 세 번째 {}는 vk::ImageLayout의 기본값이 eUndefined이므로 기본값으로 명시했습니다. 5·6번째 값은 해당 배리어가 독점적(exclusive)인지, 아니면 큐 간에 공유되는지에 대한 변수인데, 이 튜토리얼에서는 해당 내용은 다루지 않을 것입니다2. 마지막 vk::ImageSubresourceRange 는 해당 배리어가 이미지 뷰의 것과 마찬가지로 0번째 레이어/밉 레벨에 작용할 것을 명시합니다.
커맨드 버퍼에 파이프라인 배리어를 적용하기 위해서는 pipelineBarrier 메서드를 사용하여 해당 커맨드 버퍼 전후로 기록된 커맨드 간 파이프라인 배리어를 명시합니다. 앞서 설명했듯 적절한 파이프라인 스테이지와 3번째 인수부터 의존성 플래그 (dependency flags), 메모리 배리어, 버퍼 메모리 배리어, 이미지 메모리 배리어 순으로 필요한 배리어를 설정하면 됩니다.
코드를 입력했으면 프로젝트를 실행하여 검증 레이어가 오류 없이 실행되는지 확인해보세요.
이미지를 호스트에서 접근 가능한 선형 이미지로 복사하기
과연 이미지가 우리의 의도에 맞게 잘 만들어졌을까요? 이를 확인하기 위해 생성한 격자 이미지를 파일로 저장해보겠습니다. 우리는 이미지 출력 라이브러리로 stb_image를 이용하겠습니다.
일단 이미지를 이 라이브러리를 이용해 저장하려면 이미지의 데이터가 행-우선 선형 형식이어야 합니다. 선형 형식이라는 말은, 이미지 타일링에서 설명했듯 각 텍셀이 메모리에 순차적으로 존재해야 함을 의미합니다. 하지만 지금 우리의 이미지 타일링은 eOptimal이므로, 이 타일링을 eLinear 로 바꿀 방법을 고민해보아야 합니다.
이미 생성한 이미지의 타일링을 바꿀 방법은 없지만, Vulkan에서는 서로 다른 타일링을 가지는 이미지간의 복사를 지원합니다. 즉, 우리가 선형 타일링을 갖는 이미지 linearImage를 만들고, 원래 image로부터 복사한 후, linearImage의 디바이스 메모리를 매핑하여 데이터를 얻을 수 있습니다.
먼저 선형 이미지와 그 디바이스 메모리를 생성해 보겠습니다.
Subject: [PATCH] Create linear image for copy destination.
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -154,6 +154,23 @@
vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
} };
+ const vk::raii::Image linearImage { device, vk::ImageCreateInfo {
+ {},
+ vk::ImageType::e2D,
+ vk::Format::eR8G8B8A8Unorm,
+ { 512, 512, 1 },
+ 1, 1,
+ vk::SampleCountFlagBits::e1,
+ vk::ImageTiling::eLinear,
+ {},
+ } };
+
+ const vk::raii::DeviceMemory linearImageMemory { device, vk::MemoryAllocateInfo {
+ linearImage.getMemoryRequirements().size,
+ getMemoryTypeIndex(vk::MemoryPropertyFlagBits::eHostVisible),
+ } };
+ linearImage.bindMemory(*linearImageMemory, 0);
+
// Create descriptor set layout.
const vk::raii::DescriptorSetLayout descriptorSetLayout = [&] {
constexpr vk::DescriptorSetLayoutBinding layoutBinding {
이미지의 형식이나 크기 등은 동일하며, 선형 타일링으로 변경됐습니다. 이전 image는 스토리지 이미지 용도로 사용됐으나, 지금 linearImage는 아직 용도를 모르니 비워둡시다. 더불어, 이미지 디바이스 메모리 또한 eHostVisible로 변경되어 그 데이터를 매핑할 수 있게 하였습니다 (어차피 이미지에 쓰기 연산을 할 필요는 없으므로 eHostCoherent는 불필요합니다).
이제 image와 linearImage는 서로 복사되는 관계이고, 그 중에서도 image는 복사되는 쪽, linearImage는 복사받는 쪽이므로, 서로의 용도에 각각 eTransferSrc와 eTransferDst를 포함하여야 합니다.
Subject: [PATCH] Change image usages.
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -135,7 +135,7 @@
1, 1,
vk::SampleCountFlagBits::e1,
vk::ImageTiling::eOptimal,
- vk::ImageUsageFlagBits::eStorage,
+ vk::ImageUsageFlagBits::eStorage | vk::ImageUsageFlagBits::eTransferSrc,
} };
const vk::raii::DeviceMemory imageMemory { device, vk::MemoryAllocateInfo {
@@ -162,7 +162,7 @@
1, 1,
vk::SampleCountFlagBits::e1,
vk::ImageTiling::eLinear,
- {},
+ vk::ImageUsageFlagBits::eTransferDst,
} };
const vk::raii::DeviceMemory linearImageMemory { device, vk::MemoryAllocateInfo {
이제 두 이미지를 복사하는 커맨드를 커맨드 버퍼에 기록해보겠습니다. 복사는 컴퓨트 셰이더가 끝난 후 이루어져야 할 것이니 해당 커맨드 뒤에 위치하며, copyImage 메서드를 사용하여 이루어집니다.
Subject: [PATCH] Copy from image to linearImage.
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -279,6 +279,18 @@
commandBuffer.bindDescriptorSets(vk::PipelineBindPoint::eCompute, *pipelineLayout, 0, descriptorSet, {});
commandBuffer.dispatch(512 / 16, 512 / 16, 1);
+ // Copy from image to linearImage.
+ commandBuffer.copyImage(
+ *image, vk::ImageLayout::eTransferSrcOptimal,
+ *linearImage, vk::ImageLayout::eTransferDstOptimal,
+ vk::ImageCopy {
+ vk::ImageSubresourceLayers { vk::ImageAspectFlagBits::eColor, 0, 0, 1 },
+ vk::Offset3D{},
+ vk::ImageSubresourceLayers { vk::ImageAspectFlagBits::eColor, 0, 0, 1 },
+ vk::Offset3D{},
+ vk::Extent3D { 512, 512, 1 },
+ });
+
commandBuffer.end();
// Submit commandBuffer to computeQueue and wait for it to finish.
이 메서드의 인수는 다음과 같습니다:
srcImage: 복사될 이미지입니다.srcImageLayout: 복사될 이미지의 레이아웃입니다. Vulkan 명세에 따르면SHARED_PRESENT_OPTIMAL,TRANSFER_SRC_OPTIMAL,GENERAL세 레이아웃만이 가능하다고 하나, 이름에서 알 수 있듯이TRANSFER_SRC_OPTIMAL이 가장 적합합니다.dstImage: 복사받을 이미지입니다.dstImageLayout: 복사받을 이미지의 레이아웃입니다. 이 또한TRANSFER_DST_OPTIMAL이 가장 적합합니다.regions: 이는vk::ArrayProxy<const vk::ImageCopy>타입으로, 복사할 영역 배열을 명시합니다.srcSubresource: 복사할 이미지의 영역으로,vk::ImageSubresourceLayers타입입니다.
이는vk::ImageSubresourceRange와 다르게 오직 하나의 밉 레벨만을 명시할 수 있습니다. 0번째 밉 레벨과 0번째 레이어를 명시했습니다.srcOffset: 복사할 영역의 3차원 시작 좌표로, 우리는 전체 영역을 복사하므로 기본값(vk::Offset3D { 0, 0, 0 })을 사용합니다.dstSubresource,dstOffset: 복사받을 이미지에 대해 이전과 같은 개념입니다.extent: 복사할 영역의 크기입니다. 우리는 전체 이미지를 복사하므로 이미지의 크기vk::Extent3D { 512, 512, 1 }를 사용합니다.
regions인수의 타입인vk::ArrayProxy<T>는vk::ArrayProxyNoTemporaries<T>와 달리 그 객체가 임시 객체임을 허용합니다. 따라서 이 경우vk::ImageCopy를 별도 변수로 선언하지 않고, 바로 대입할 수 있습니다.
copyImage를 비롯한copyBuffer,copyImageToBuffer,copyBufferToImage등의 전송(transfer)와 관련된 메서드는 해당 커맨드 버퍼의 큐 패밀리가 전송을 지원해야 합니다 (즉,eTransfer가queueFlags에 포함되어 있어야 합니다). Vulkan 명세에 따라 컴퓨트 및 그래픽스 큐 패밀리는 암시적으로 전송을 지원하므로, 본 튜토리얼에서는 이러한 전송 큐를 따로 만들지는 않습니다. 다만, 어떤 시스템에는 전송에 특화된 큐가 있는 경우도 있으니, 이 경우에는 해당 큐를 사용하여 전송을 수행하는 것이 좋습니다.
또한 메서드에 명시된 바와 같이 이미지 레이아웃을 변경해야 할테니 해당 파이프라인 배리어를 커맨드 사이에 추가하겠습니다.
Subject: [PATCH] Change image layouts to appropriate value between commands.
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -279,6 +279,29 @@
commandBuffer.bindDescriptorSets(vk::PipelineBindPoint::eCompute, *pipelineLayout, 0, descriptorSet, {});
commandBuffer.dispatch(512 / 16, 512 / 16, 1);
+ // Change image layout to TRANSFER_SRC_OPTIMAL, and linearImage layout to TRANSFER_DST_OPTIMAL.
+ {
+ const std::array barriers {
+ vk::ImageMemoryBarrier {
+ vk::AccessFlagBits::eShaderWrite, vk::AccessFlagBits::eTransferRead,
+ vk::ImageLayout::eGeneral, vk::ImageLayout::eTransferSrcOptimal,
+ {}, {},
+ *image,
+ vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
+ },
+ vk::ImageMemoryBarrier {
+ {}, vk::AccessFlagBits::eTransferWrite,
+ {}, vk::ImageLayout::eTransferDstOptimal,
+ {}, {},
+ *linearImage,
+ vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
+ },
+ };
+ commandBuffer.pipelineBarrier(
+ vk::PipelineStageFlagBits::eComputeShader, vk::PipelineStageFlagBits::eTransfer,
+ {}, {}, {}, barriers);
+ }
+
// Copy from image to linearImage.
commandBuffer.copyImage(
*image, vk::ImageLayout::eTransferSrcOptimal,
이번에는 두 개의 이미지 메모리 배리어가 필요하므로, 해당 배리어들을 배열로 묶어 바로 전달했습니다. 첫 번째 원소는 image 레이아웃을 eTransferSrcOptimal로 변경, 두 번째는 linearImage 레이아웃을 eTransferDstOptimal로 변경합니다. 접근 마스크 또한 첫 번째 배리어는 셰이더 쓰기 -> 복사 읽기 순, 두 번째 배리어는 () -> 복사 쓰기 순으로 올바르게 설정됐습니다.
참고로, 이미지 메모리 배리어에서 변경 전 레이아웃은 그게 무엇인지에 관계 없이
{}(vk::ImageLayout::eUndefined)로 전달해도 괜찮습니다. 이 경우 드라이버가 자체적으로 이미지 레이아웃을 판단하고 적절히 배리어를 수행할 수 있습니다. 하지만 성능이 하락할 수 있으므로 지금처럼 레이아웃의 추적이 용이한 경우 변경 전 레이아웃을 명시하는 것이 좋습니다.
코드 작성을 완료했으면 이전과 마찬가지로 프로젝트를 실행하여 정상 종료되는지 확인하세요.
미리 예고하자면, 지금과 같이 디바이스 이미지를 호스트 이미지로 복사하는 과정을 반대로 하면, “텍스쳐 불러오기”가 됩니다. 이 작업은 흔히 스테이징(staging)이라고 불리는 작업이며, 이는 사실 선형 타일링 이미지가 아닌 버퍼로도 할 수 있습니다. 이후 튜토리얼에서는 이러한 작업을 할 것입니다.
마무리: 파일 I/O
stb_image.h 헤더 파일을 그대로 복사해서 프로젝트에 추가할 수도 있지만, 추후 GLM이나 GLFW 등 다른 라이브러리도 추가할 것이기 때문에 우리는 vcpkg를 이용해 의존성을 관리할 것입니다. 해당 사이트의 가이드를 따라 vcpkg를 설치하고, 터미널에 다음 두 명령을 입력하여
1
2
vcpkg --version
echo $VCPKG_ROOT
를 실행하여 vcpkg가 PATH에 선언됐고, VCPKG_ROOT 환경 변수가 잘 등록됐는지 확인하세요.
프로젝트 폴더를 연 후 다음 명령어를 실행하여 stb를 설치하세요.
1
2
vcpkg new --application # 이 명령어는 프로젝트에 vcpkg 메니페스트 파일을 생성합니다.
vcpkg add port stb # 이 명령어는 stb 라이브러리를 설치합니다.
Subject: [PATCH] Add vcpkg, install stb.
---
Index: src/vcpkg-configuration.json
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/vcpkg-configuration.json b/src/vcpkg-configuration.json
new file mode 100644
--- /dev/null
+++ b/src/vcpkg-configuration.json
@@ -0,0 +1,14 @@
+{
+ "default-registry": {
+ "kind": "git",
+ "baseline": "055721089e8037d4d617250814d11f881e557549",
+ "repository": "https://github.com/microsoft/vcpkg"
+ },
+ "registries": [
+ {
+ "kind": "artifact",
+ "location": "https://github.com/microsoft/vcpkg-ce-catalog/archive/refs/heads/main.zip",
+ "name": "microsoft"
+ }
+ ]
+}
Index: src/vcpkg.json
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/vcpkg.json b/src/vcpkg.json
new file mode 100644
--- /dev/null
+++ b/src/vcpkg.json
@@ -0,0 +1,5 @@
+{
+ "dependencies": [
+ "stb"
+ ]
+}
다음과 같은 두 파일이 생성될 것입니다. 이제 CMake 프로젝트의 CMAKE_TOOLCHAIN_FILE 변수를 $VCPKG_ROOT/scripts/buildsystems/vcpkg.cmake로 선언하여 CMake가 vcpkg를 사용할 수 있게 합니다. 저는 IDE를 통해 등록하였습니다.
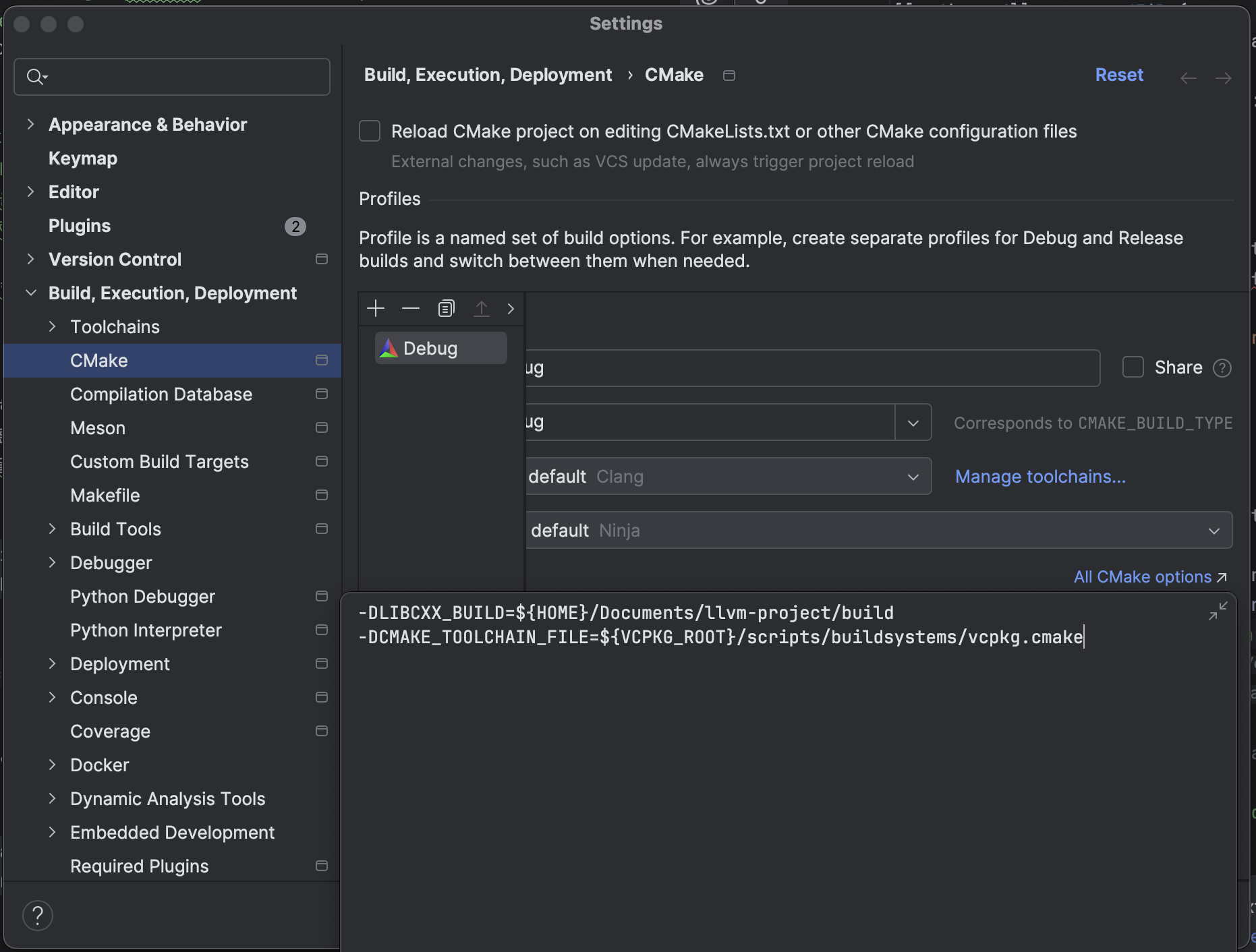
CMAKE_TOOLCHAIN_FILE을 vcpkg CMake 스크립트로 등록한 모습
이제 CMake의 find_package 구문을 이용하여 Stb 라이브러리를 추가할 수 있습니다. 이 라이브러리에는 stb_image가 포함됩니다.
Subject: [PATCH] Add Stb dependency to CMake.
---
Index: src/02_compute-image/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/CMakeLists.txt b/src/02_compute-image/CMakeLists.txt
--- a/src/02_compute-image/CMakeLists.txt
+++ b/src/02_compute-image/CMakeLists.txt
@@ -3,6 +3,7 @@
# --------------------
add_executable(02_compute-image main.cpp)
+target_include_directories(02_compute-image PRIVATE ${Stb_INCLUDE_DIR})
target_link_libraries(02_compute-image PRIVATE VulkanHppModule)
# --------------------
Index: src/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/CMakeLists.txt b/src/CMakeLists.txt
--- a/src/CMakeLists.txt
+++ b/src/CMakeLists.txt
@@ -22,6 +22,7 @@
# External dependencies.
# --------------------
+find_package(Stb REQUIRED)
find_package(Vulkan REQUIRED)
# --------------------
stb_image의 사용 방법은 해당 헤더 파일의 머릿글을 확인하세요. impl.cpp 파일을 만들어 헤더 파일의 구현부를 정의하고, 이미지 데이터를 매핑하여 output.png로 저장하겠습니다.
Subject: [PATCH] Write image to output.png
---
Index: src/02_compute-image/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/CMakeLists.txt b/src/02_compute-image/CMakeLists.txt
--- a/src/02_compute-image/CMakeLists.txt
+++ b/src/02_compute-image/CMakeLists.txt
@@ -2,7 +2,7 @@
# Project executables.
# --------------------
-add_executable(02_compute-image main.cpp)
+add_executable(02_compute-image main.cpp impl.cpp)
target_include_directories(02_compute-image PRIVATE ${Stb_INCLUDE_DIR})
target_link_libraries(02_compute-image PRIVATE VulkanHppModule)
Index: src/02_compute-image/impl.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/impl.cpp b/src/02_compute-image/impl.cpp
new file mode 100644
--- /dev/null
+++ b/src/02_compute-image/impl.cpp
@@ -0,0 +1,2 @@
+#define STB_IMAGE_WRITE_IMPLEMENTATION
+#include <stb_image_write.h>
\ No newline at end of file
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -1,4 +1,4 @@
-#include <cassert>
+#include <stb_image_write.h>
import std;
import vulkan_hpp;
@@ -323,4 +323,8 @@
commandBuffer,
});
computeQueue.waitIdle();
+
+ const void* const data = (*device).mapMemory(*linearImageMemory, 0, vk::WholeSize);
+ stbi_write_png("output.png", 512, 512, 4, data, 512 * 4);
+ (*device).unmapMemory(*linearImageMemory);
}
\ No newline at end of file
stbi_write_png의 마지막 인수는 이미지의 한 행이 총 몇 바이트인지를 나타내며, 우리의 이미지는 텍셀당 4바이트이므로 512 * 4를 전달했습니다. 프로젝트를 실행하여 실행 파일이 위치한 디렉터리에 output.png 파일이 생성되는지 확인하세요.
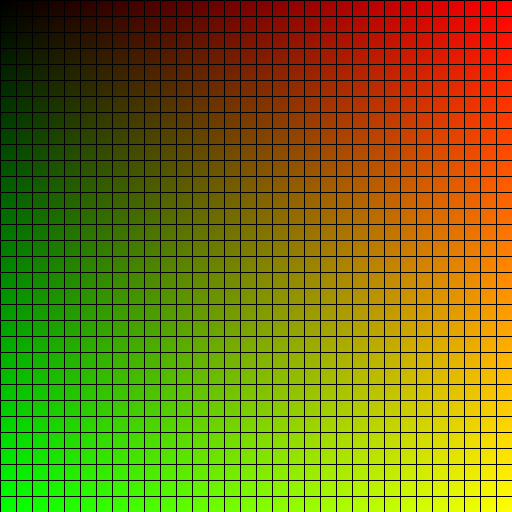 멋진 그래디언트 격자가 완성되었습니다.
멋진 그래디언트 격자가 완성되었습니다.
이제 이미지를 생성하고, 컴퓨트 셰이더를 이용해 이미지를 수정하고, 그 결과를 파일로 저장하는 프로젝트를 완성했습니다. 이번 튜토리얼에서는 이미지의 레이아웃을 변경하는 방법과, 이미지를 호스트에서 접근 가능한 선형 이미지로 복사하는 방법을 배웠습니다.
비록 지금은 그래픽스 파이프라인보다 컴퓨트 파이프라인이 더 간단하기에 이러한 방법으로 이미지를 생성해내고 있지만, 난이도와 별개로 컴퓨트 파이프라인은 이러한 분야로 점점 더 사용이 늘어나고 있습니다. 컴퓨트 파이프라인은 그래픽스 파이프라인에 필요한 ROP (Render output unit)을 요구하지 않기 때문에 더 빠르고 간결하게 실행될 수 있습니다. 다만 아직 메모리 대역폭이 한정적인 모바일 기기에서는 타일 렌더링에 의해 그래픽스 파이프라인을 더 많이 사용하는 편입니다3.
다음은 몇 가지 컴퓨트 셰이더 코드 예제입니다. grid.comp를 다음 코드로 바꿔보며, 컴퓨트 셰이더의 매력을 느껴보세요.
- 셰이더 코드:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
#version 450 const uint MAX_ITERATION = 200; const vec2 C = vec2(-0.4, 0.6); layout (set = 0, binding = 0, rgba8) writeonly uniform image2D outputImage; layout (local_size_x = 16, local_size_y = 16) in; void main(){ uvec2 outputImageSize = imageSize(outputImage); vec2 z = mix(vec2(-2), vec2(2), vec2(gl_GlobalInvocationID.xy) / outputImageSize); uint iter_count = 0; for (; iter_count < MAX_ITERATION; ++iter_count){ z = vec2(z.x * z.x - z.y * z.y, 2 * z.x * z.y) + C; if (length(z) > 2){ break; } } vec3 color = vec3(float(iter_count) / MAX_ITERATION); imageStore(outputImage, ivec2(gl_GlobalInvocationID.xy), vec4(color, 1.0)); }

셰이더 코드: 여기를 참조하세요. 이 코드는 ShaderToy의 Shane에 의해 작성된 코드를 Vulkan에서 사용 가능하도록 살짝 수정됐습니다.

다음 튜토리얼부터는 본격적으로 그래픽스 파이프라인에 대해 다루고, 드디어 우리가 원하는 삼각형을 그릴 것입니다. 이번 튜토리얼의 전체 코드 변경 사항은 다음과 같습니다.
Subject: [PATCH] Write image to output.png
Add Stb dependency to CMake.
Add vcpkg, install stb.
Change image layouts to appropriate value between commands.
Copy from image to linearImage.
Change image usages.
Create linear image for copy destination.
Change image layout to GENERAL before compute pipeline dispatch
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -1,4 +1,4 @@
-#include <cassert>
+#include <stb_image_write.h>
import std;
import vulkan_hpp;
@@ -135,7 +135,7 @@
1, 1,
vk::SampleCountFlagBits::e1,
vk::ImageTiling::eOptimal,
- vk::ImageUsageFlagBits::eStorage,
+ vk::ImageUsageFlagBits::eStorage | vk::ImageUsageFlagBits::eTransferSrc,
} };
const vk::raii::DeviceMemory imageMemory { device, vk::MemoryAllocateInfo {
@@ -154,6 +154,23 @@
vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
} };
+ const vk::raii::Image linearImage { device, vk::ImageCreateInfo {
+ {},
+ vk::ImageType::e2D,
+ vk::Format::eR8G8B8A8Unorm,
+ { 512, 512, 1 },
+ 1, 1,
+ vk::SampleCountFlagBits::e1,
+ vk::ImageTiling::eLinear,
+ vk::ImageUsageFlagBits::eTransferDst,
+ } };
+
+ const vk::raii::DeviceMemory linearImageMemory { device, vk::MemoryAllocateInfo {
+ linearImage.getMemoryRequirements().size,
+ getMemoryTypeIndex(vk::MemoryPropertyFlagBits::eHostVisible),
+ } };
+ linearImage.bindMemory(*linearImageMemory, 0);
+
// Create descriptor set layout.
const vk::raii::DescriptorSetLayout descriptorSetLayout = [&] {
constexpr vk::DescriptorSetLayoutBinding layoutBinding {
@@ -241,11 +258,62 @@
1,
}).front();
- // Record commands that invoke computePipeline.
commandBuffer.begin({ vk::CommandBufferUsageFlagBits::eOneTimeSubmit });
+
+ // Change image layout to GENERAL.
+ {
+ const vk::ImageMemoryBarrier barrier {
+ {}, vk::AccessFlagBits::eShaderWrite,
+ {}, vk::ImageLayout::eGeneral,
+ {}, {},
+ *image,
+ vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
+ };
+ commandBuffer.pipelineBarrier(
+ vk::PipelineStageFlagBits::eTopOfPipe, vk::PipelineStageFlagBits::eComputeShader,
+ {}, {}, {}, barrier);
+ }
+
+ // Invoke computePipeline.
commandBuffer.bindPipeline(vk::PipelineBindPoint::eCompute, *computePipeline);
commandBuffer.bindDescriptorSets(vk::PipelineBindPoint::eCompute, *pipelineLayout, 0, descriptorSet, {});
commandBuffer.dispatch(512 / 16, 512 / 16, 1);
+
+ // Change image layout to TRANSFER_SRC_OPTIMAL, and linearImage layout to TRANSFER_DST_OPTIMAL.
+ {
+ const std::array barriers {
+ vk::ImageMemoryBarrier {
+ vk::AccessFlagBits::eShaderWrite, vk::AccessFlagBits::eTransferRead,
+ vk::ImageLayout::eGeneral, vk::ImageLayout::eTransferSrcOptimal,
+ {}, {},
+ *image,
+ vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
+ },
+ vk::ImageMemoryBarrier {
+ {}, vk::AccessFlagBits::eTransferWrite,
+ {}, vk::ImageLayout::eTransferDstOptimal,
+ {}, {},
+ *linearImage,
+ vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
+ },
+ };
+ commandBuffer.pipelineBarrier(
+ vk::PipelineStageFlagBits::eComputeShader, vk::PipelineStageFlagBits::eTransfer,
+ {}, {}, {}, barriers);
+ }
+
+ // Copy from image to linearImage.
+ commandBuffer.copyImage(
+ *image, vk::ImageLayout::eTransferSrcOptimal,
+ *linearImage, vk::ImageLayout::eTransferDstOptimal,
+ vk::ImageCopy {
+ vk::ImageSubresourceLayers { vk::ImageAspectFlagBits::eColor, 0, 0, 1 },
+ vk::Offset3D{},
+ vk::ImageSubresourceLayers { vk::ImageAspectFlagBits::eColor, 0, 0, 1 },
+ vk::Offset3D{},
+ vk::Extent3D { 512, 512, 1 },
+ });
+
commandBuffer.end();
// Submit commandBuffer to computeQueue and wait for it to finish.
@@ -255,4 +323,8 @@
commandBuffer,
});
computeQueue.waitIdle();
+
+ const void* const data = (*device).mapMemory(*linearImageMemory, 0, vk::WholeSize);
+ stbi_write_png("output.png", 512, 512, 4, data, 512 * 4);
+ (*device).unmapMemory(*linearImageMemory);
}
\ No newline at end of file
Index: src/vcpkg-configuration.json
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/vcpkg-configuration.json b/src/vcpkg-configuration.json
new file mode 100644
--- /dev/null
+++ b/src/vcpkg-configuration.json
@@ -0,0 +1,14 @@
+{
+ "default-registry": {
+ "kind": "git",
+ "baseline": "055721089e8037d4d617250814d11f881e557549",
+ "repository": "https://github.com/microsoft/vcpkg"
+ },
+ "registries": [
+ {
+ "kind": "artifact",
+ "location": "https://github.com/microsoft/vcpkg-ce-catalog/archive/refs/heads/main.zip",
+ "name": "microsoft"
+ }
+ ]
+}
Index: src/vcpkg.json
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/vcpkg.json b/src/vcpkg.json
new file mode 100644
--- /dev/null
+++ b/src/vcpkg.json
@@ -0,0 +1,5 @@
+{
+ "dependencies": [
+ "stb"
+ ]
+}
Index: src/02_compute-image/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/CMakeLists.txt b/src/02_compute-image/CMakeLists.txt
--- a/src/02_compute-image/CMakeLists.txt
+++ b/src/02_compute-image/CMakeLists.txt
@@ -2,7 +2,8 @@
# Project executables.
# --------------------
-add_executable(02_compute-image main.cpp)
+add_executable(02_compute-image main.cpp impl.cpp)
+target_include_directories(02_compute-image PRIVATE ${Stb_INCLUDE_DIR})
target_link_libraries(02_compute-image PRIVATE VulkanHppModule)
# --------------------
Index: src/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/CMakeLists.txt b/src/CMakeLists.txt
--- a/src/CMakeLists.txt
+++ b/src/CMakeLists.txt
@@ -22,6 +22,7 @@
# External dependencies.
# --------------------
+find_package(Stb REQUIRED)
find_package(Vulkan REQUIRED)
# --------------------
Index: src/02_compute-image/impl.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/impl.cpp b/src/02_compute-image/impl.cpp
new file mode 100644
--- /dev/null
+++ b/src/02_compute-image/impl.cpp
@@ -0,0 +1,2 @@
+#define STB_IMAGE_WRITE_IMPLEMENTATION
+#include <stb_image_write.h>
\ No newline at end of file
Write-After-Read hazard; WAR. ↩
우리는 모든 자원을 독점적으로 사용하고, 추후 필요할 경우 큐 패밀리 소유권 전송(queue family ownership transfer)를 이용할 것입니다. ↩
타일 렌더링 시스템에서는 대역폭 문제로 이미지를 타일(tile)로 분할하여 각 타일 별로 연산을 수행합니다. 프라그멘트 셰이더는 해당 셰이더가 현재 타일의 픽셀에만 쓰기 연산을 함이 보장되지만, 컴퓨트 셰이더는 어떤 invocation이 이에 대응하는 픽셀에만 접근한다는 보장이 없기 때문에, 타일 렌더링의 이점을 누릴 수 없습니다. 이에 대해서 관련 proposal이 나왔으니, 관심이 있으시면 읽어보시기 바랍니다. ↩