Vulkan 튜토리얼: 컴퓨트 파이프라인 생성하기
이번 튜토리얼에서는 버퍼 원소의 두 배를 계산하는 과정을 어떻게 GPU 코드로 나타낼 수 있는지에 대해 알아보겠습니다.
앞선 C++의 코드로 GPU를 조작하는 과정은 호스트에서 실행되는 것과 달리, 이번에는 디바이스에서 병렬적으로 실행될 수 있는 셰이더를 사용할 것입니다. 셰이더는 GPU에 포함된 수많은 코어에서 병렬적으로 실행됩니다. 이 코어의 수는 CPU의 개수를 아득히 능가하나1, 범용적 목적의 CPU 코어와는 다르게 단순 산술 연산에 치중되어 있기 때문에 분기 등의 비순차적 흐름에는 취약합니다. 이러한 특징과 제약 조건에 따라, 셰이더 프로그래밍은 기존과는 다소 다른 양상을 보입니다.
Vulkan에서는 셰이더를 만들기 위해 SPIR-V라는 컴파일된 저수준 언어를 사용합니다. 하지만 우리가 직접 셰이더 프로그래밍을 SPIR-V로 할 필요는 없습니다. SPIR-V는 GLSL이나 HLSL과 같은 고수준 셰이딩 언어로부터 컴파일될 수 있습니다. 이처럼 SPIR-V는 여러 프론트 엔드 언어로부터 컴파일될 수 있음에 따라, 개발자에게 다양한 셰이딩 언어 선택권을 제공하고, 미리 드라이버에 최적화된 저수준 코드를 제공함에 따라 셰이더를 해석하고 생성하는 시간을 줄일 수 있습니다.
우리는 고수준 셰이딩 언어로 GLSL을 사용할 것입니다. GLSL을 SPIR-V로 컴파일하기 위해서는 glslc가 필요하며, 이는 Vulkan SDK를 처음 설치할 때 같이 설치됩니다.
그러면 지금부터 버퍼 원소의 두 배를 계산하는 셰이더를 작성해보겠습니다.
셰이더 작성하기
컴퓨트 셰이더의 실행 모델
우리가 작성할 셰이더는 컴퓨트 셰이더(compute shader)로, 임의의 데이터를 계산할 수 있는 셰이더입니다. 컴퓨트 셰이더가 GPU에서 어떻게 병렬적으로 실행되는지에 대한 실행 모델을 알아보겠습니다. 일단 다음의 용어를 이해해야 합니다.
- 워크 그룹 (work group)
- invocation
우리에게 다음과 같이 32개의 작업이 주어졌다고 가정해봅시다.

초록색 상자 32개 각각은 invocation을 나타냅니다. 각각의 invocation에서 독립적으로 셰이더가 실행됩니다.
이 invocation을 8개씩 모아 워크 그룹을 만들었습니다. 워크 그룹은 사용자가 실행(execute)할 수 있는 컴퓨트 연산의 최소 단위입니다. 즉, 우리는 각 invocation 개별로 실행하는 것이 아닌, invocation을 모은 워크 그룹을 몇 개 실행할 것인지를 정할 수 있습니다. 총 32개의 invocation을 실행하기 위해서는 4개의 워크 그룹을 실행해야 합니다.
GPU의 연산을 invocation과 워크 그룹이라는 추상적인 단위로 나눈 것은 비록 셰이더가 각 invocation에서 독립적으로 실행되지만, 같은 워크 그룹 내에서는 여러 가지 특별한 동기화를 할 수 있습니다. 예를 들면, 같은 워크 그룹의 invocation간에는 코드의 특정 시점에서 서로 동기화를 할 수 있거나2, 전체 데이터보다 빠르게 공유하고 읽고 쓸 수 있는 공용 메모리 (shared memory)가 주어지기도 합니다.
이러한 실행 모델은 최대 3차원까지 확장될 수 있습니다. 예를 들어, 우리가 다루는 작업이 이미지 처리로, 각 픽셀의 값을 결정하는 것이라고 생각해봅시다. 16x8 크기의 이미지를 실행 모델로 나타내 보겠습니다.
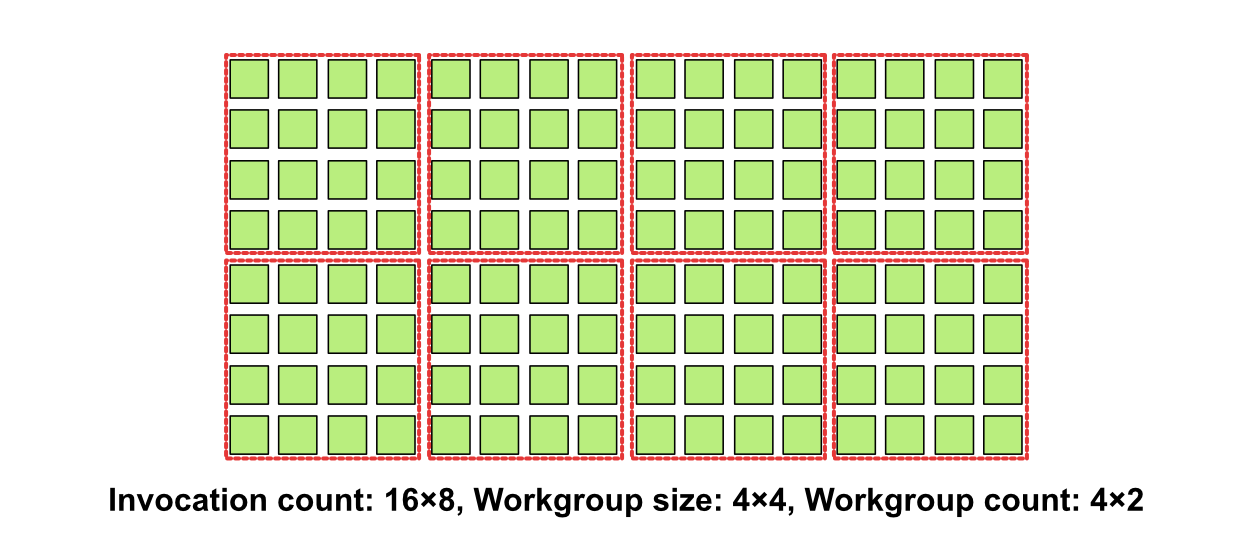
이 경우 invocation은 16×8=128개, 워크 그룹은 개당 4×4=16의 크기를 갖는 4×2=8개의 워크 그룹이 있을 것입니다.
만일 전체 invocation이 워크 그룹 크기의 배수가 아니라면 어떻게 할까요? 다음과 같이 15x6 크기의 이미지를 실행 모델로 나타내 보겠습니다.
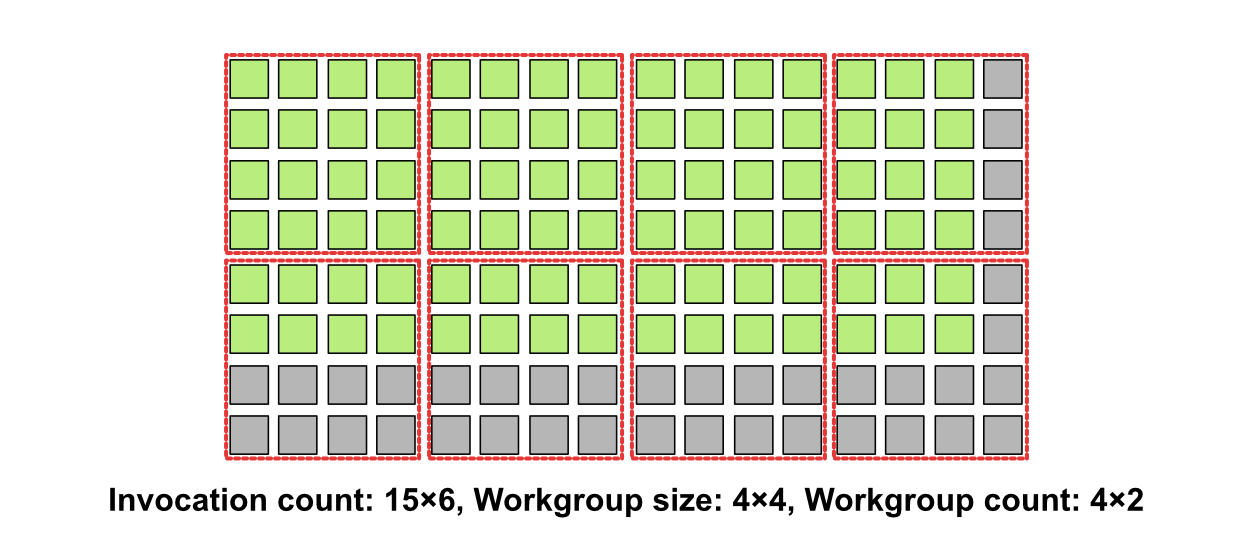
이 경우, 컴퓨트 셰이더를 실행할 수 있는 최소의 단위가 워크 그룹이기 때문에, 우리는 설사 16번째 열과 7·8번째 행의 invocation을 실행할 필요가 없음에도 불구하고 이들을 실행해야 합니다. 이 경우 셰이더에서는 현재 속한 invocation의 위치를 얻어, 만일 내가 속한 위치가 실행될 필요가 없다면 해당 경우에 대한 추가적인 실행 흐름을 작성해야 합니다. 이러한 분기 명령은 GPU에 취약하므로, invocation의 개수를 워크 그룹의 크기의 배수가 되도록 하는 것이 성능상 더 유리합니다.
위 그림은 실행 모델을 나타내기 위해 작은 워크 그룹 크기를 사용했으나, 실제 GPU는 대량의 invocation을 실행해야 하고 (1920x1080 크기의 이미지를 생각해보세요.) 따라서 더 큰 워크 그룹의 크기를 사용합니다. 이는 GPU 제조사마다 다르지만, NVIDIA의 GPU는 워크 그룹의 크기를 323로, AMD는 64의 배수4로 사용할 것을 권장하고 있습니다. 좋은 워크 그룹의 크기는 충분한 프로파일링을 거쳐 경험적으로 얻어낼 수 있으며, 우리는 일관성을 위해 256 (1차원) 또는 16×16 (2차원) 크기의 워크 그룹을 사용하겠습니다.
셰이더 작성하기
이러한 실행 모델을 이해했으니 이제는 실제 셰이더 코드를 작성해보겠습니다. shaders 폴더를 생성하고 다음과 같은 multiply.comp 코드를 작성하겠습니다.
Subject: [PATCH] Add compute shader that multiply 2 to the floats.
---
Index: src/shaders/multiply.comp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/shaders/multiply.comp b/src/shaders/multiply.comp
new file mode 100644
--- /dev/null
+++ b/src/shaders/multiply.comp
@@ -0,0 +1,10 @@
+#version 450
+
+layout (set = 0, binding = 0) buffer Ssbo { float data[]; };
+
+layout (local_size_x = 256) in;
+
+void main(){
+ uint index = gl_GlobalInvocationID.x;
+ data[index] *= 2.0;
+}
\ No newline at end of file
갑자기 많은 코드가 추가되었네요! 이 코드를 하나하나 따져보겠습니다.
- 맨 위
#version 450은 우리가 사용할 GLSL의 버전입니다. GLSL 또한 크로노스 그룹이 관리하고 있는 명세를 따르며,450은 OpenGL 4.5의 명세를 따르겠다는 뜻입니다. 이 버전은 컴퓨트 셰이더를 비롯한 모든 셰이더의 첫 줄에 명시되어야 합니다. layout (set = 0, binding = 0) buffer Ssbo { float data[]; }는 많은 의미를 담고 있습니다.layout (set = 0, binding = 0) buffer ...구문은 우리가 다룰 데이터를 셰이더가 어떻게 찾을지에 대한 정보입니다. 이 데이터는 0번째 셋과 0번째 바인딩에 위치하며, 그 종류가 버퍼임을 의미합니다. 왜 이 데이터가 하나의 위치가 아닌 두 개 (셋, 바인딩)의 위치에 따라 접근되어야 하는지에 대해서는 아래에 설명하겠습니다.... Ssbo { float data[]; }구문은 이 버퍼를Ssbo라는 이름의 구조체로 보겠다는 의미이며, 그 안float data[]를 통해 이 구조체가float의 임의 크기 배열로 이루어져 있다는 뜻입니다. 이 구조체의 변수명이 설정되지 않았기 때문에, 우리는 이후 코드에서data[3]과 같이 버퍼의 원소를 인덱스로 접근할 수 있습니다.
layout (local_size_x = 256) in;은 앞서 설명한 실행 모델의 워크 그룹 크기를 나타냅니다. 원래layout내 괄호에는local_size_x,local_size_y,local_size_z로 각각 워크 그룹의 가로(x)·세로(y)·깊이(z)의 크기를 지정할 수 있으나, 이들의 기본값이 1로 설정되어 있기 때문에 현재 1차원 데이터를 다루는 입장에서는local_size_x만 256으로 명시해도 충분합니다. 이 값은 상수여야 합니다.void main() { ... }은 셰이더의 진입점 (entry point)입니다. C++와는 달리main이 아닌 다른 이름으로도 정의될 수 있으나, 특별한 이유가 없다면main을 써줍시다5.uint index = gl_GlobalInvocationID.x;구문의gl_GlobalInvocationID는 컴퓨트 셰이더에서 기본 제공하는 변수로, 현재 셰이더가 실행되는 invocation의 위치를 3차원 음이 아닌 정수 벡터(uvec3)로 나타낸 것입니다. 즉, 이 값은 모든 invocation마다 다른 값을 가지며, 우리가 앞서 나타낸 위 32개의 1차원 invocation 그림을 예로 들면 왼쪽에서 5번째 invocation은uvec3(4, 0, 0)의 값을 가질 것이며, 16×8개의 2차원 invocation 그림의 우하단 invocation은uvec3(15, 7, 0)의 값을 가질 것입니다. 지금은 1차원 데이터를 다루므로 단지 1차원 인덱스만이 필요할 것이며, 따라서 우리는gl_GlobalInvocationID의 x 성분만을index변수에 저장하겠습니다.data[index] *= 2.0;은 앞서 받은 index를 이용해data의 아래첨자로 접근하여 (0부터 시작하는)index번째float타입 원소의 두 배를 계산하고, 할당하는 코드입니다.
참고로
Ssbo라는 이름은 Shader storage buffer object의 약자로, 우리의 버퍼가 셰이더 스토리지 버퍼임을 의미합니다. 앞서 버퍼의 사용 용도를vk::BufferUsageFlagBits::eStorageBuffer로 명시했음을 기억하세요.
현재의 셰이더 코드에는 실행할 워크 그룹의 개수와 실제 버퍼가 무엇인지를 명시하지 않았다는 사실에 유의하세요. 이들은 Vulkan API를 통해 제공할 것입니다. 지금 코드의 gl_GlobalInvocationID와 명시한 local_size_x가 얼마인지를 상기하세요.
셰이더 컴파일
작성된 GLSL 셰이더를 Vulkan에서 사용하기 위해선 SPIR-V 코드로 컴파일돼야 합니다. 실행 파일 glslc의 위치를 환경 변수(PATH)에 등록한 후, 터미널에 다음과 같은 코드를 입력해보세요.
1
glslc multiply.comp -o multiply.comp.spv
해당 multiply.comp 파일이 있는 디렉토리에 multiply.comp.spv가 생성된 것을 확인하세요.
지금은 컴퓨트 셰이더만을 다루고 있지만, 셰이더는 버텍스/프라그멘트/테셀레이션 컨트롤 셰이더 등 여러 가지 종류가 있고, 원래는 각 셰이더의 종류를
-stage인수로 넘겨야 합니다.glslc는 입력 파일의 확장자를 통해 이 셰이더가 어떤 종류인지를 유추할 수 있습니다. 다음은 확장자에 따른 셰이더 유추 대응입니다:
Shader Stage Shader File Extension <stage>vertex .vertvertexfragment .fragfragmenttesselation control .tesctesscontroltesselation evaluation .tesetessevalgeometry .geomgeometrycompute .compcompute우리는
*.comp확장자를 썼으므로 컴퓨트 셰이더인 것을 유추할 수 있습니다.
CMake 스크립트를 이용하여 자동으로 셰이더를 컴파일하기
셰이더를 직접 터미널을 이용해 컴파일 할 수 있지만, 이는 다소 잊어버리기 쉬운 과정입니다. 추후 셰이더를 수정할 경우 이를 컴파일하는 것을 깜빡하여 프로그램에 반영되지 않을 수도 있고, 내가 만든 셰이더 코드를 공유할 경우 해당 사람이 코드를 실행하기 앞서 선결적으로 코드를 컴파일해야 합니다. 이러한 문제를 해결하기 위해 우리는 CMake 스크립트를 이용해 현재 프로젝트의 타겟 vulkan-tutorial이 컴파일된 셰이더 코드를 의존성으로 갖도록 하여, 반드시 셰이더 컴파일이 선행되도록 만들 수 있습니다.
Subject: [PATCH] Add CMake scripts that compiles the given shader files.
---
Index: src/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/CMakeLists.txt b/src/CMakeLists.txt
--- a/src/CMakeLists.txt
+++ b/src/CMakeLists.txt
@@ -32,4 +32,13 @@
# --------------------
add_executable(vulkan-tutorial main.cpp)
-target_link_libraries(vulkan-tutorial PRIVATE VulkanHppModule)
\ No newline at end of file
+target_link_libraries(vulkan-tutorial PRIVATE VulkanHppModule)
+
+# --------------------
+# Compile shaders.
+# --------------------
+
+include(cmake/CompileShader.cmake)
+compile_shaders(vulkan-tutorial
+ shaders/multiply.comp
+)
\ No newline at end of file
Index: src/cmake/CompileShader.cmake
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/cmake/CompileShader.cmake b/src/cmake/CompileShader.cmake
new file mode 100644
--- /dev/null
+++ b/src/cmake/CompileShader.cmake
@@ -0,0 +1,28 @@
+# Compile shader files and copy them into build directory.
+#
+# Usage:
+# compile_shaders(target
+# path1/shader1.vert
+# path2/shader2.frag
+# ...
+# )
+#
+# Result: path1/shader1.vert.spv, path2/shader2.frag.spv, ... in build directory.
+
+find_package(Vulkan COMPONENTS glslc REQUIRED)
+find_program(glslc_executable NAMES glslc HINTS Vulkan::glslc)
+
+function(compile_shaders target)
+ # Get the rest of the arguments after the target name
+ set(sources ${ARGN})
+
+ foreach(source ${sources})
+ add_custom_command(
+ OUTPUT ${CMAKE_CURRENT_BINARY_DIR}/${source}.spv
+ DEPENDS ${CMAKE_CURRENT_SOURCE_DIR}/${source}
+ DEPFILE ${CMAKE_CURRENT_SOURCE_DIR}/${source}.d
+ COMMAND ${glslc_executable} ${CMAKE_CURRENT_SOURCE_DIR}/${source} -o ${CMAKE_CURRENT_BINARY_DIR}/${source}.spv
+ )
+ target_sources(${target} PRIVATE ${CMAKE_CURRENT_BINARY_DIR}/${source}.spv)
+ endforeach()
+endfunction()
\ No newline at end of file
프로젝트 폴더에 cmake 폴더를 만들고, CompileShader.cmake 파일을 생성했습니다. 이 스크립트는 타겟과 임의 개수의 GLSL 셰이더 코드 경로를 받은 후 이를 프로젝트 바이너리 디렉터리에 출력합니다. 메인 CMakeLists.txt에 해당 스크립트를 포함한 뒤, 앞서 작성한 컴퓨트 셰이더 경로를 vulkan-tutorial 타겟의 의존성으로 넘겼습니다.
앞서 만든 multiply.comp.spv 파일을 지우고, 프로젝트를 빌드하여 프로젝트 실행 파일 경로에 shaders/multiply.comp.spv 파일이 생성된 것을 확인하세요.
디스크립터 셋 레이아웃과 파이프라인 레이아웃
컴퓨트 셰이더는 GPU에서 실행되는 코드로, Vulkan에서 바로 실행할 수는 없습니다. 해당 셰이더를 실행하기 위해서는 이를 컴퓨트 파이프라인으로 생성해야 합니다. 컴퓨트 파이프라인은 셰이더에 대한 정보와, 해당 셰이더가 사용하는 입출력 리소스에 대한 정보를 포함하고 있습니다. 즉, 우리는 컴퓨트 셰이더를 만들면서 이전에 만들었던 1,024개의 float을 담는 buffer에 대한 정보를 명시해야 합니다.
buffer가 아닌buffer에 대한 정보입니다. 이 말은 아직은buffer를 넘길 필요는 없다는 뜻으로, 뒤에서 설명할 디스크립터 셋 레이아웃과 디스크립터 셋을 구분하는 개념이니 그 의미를 놓치지 마세요.
파이프라인을 만드는 과정은 다음과 같습니다:
- 파이프라인의 입출력 리소스에 대한 정보를 갖는 디스크립터 셋 레이아웃 객체를 만듭니다.
- 디스크립터 셋 레이아웃을 포함하여, push constant라는 또다른 파이프라인의 특성 정보를 갖는 파이프라인 레이아웃(pipeline layout)을 만듭니다. 아직은 push constant에 대해서는 다루지 않습니다.
- 앞서 작성한 셰이더 코드를 불러와 셰이더 모듈 (shader module)을 만듭니다.
- 셰이더 모듈과 해당 셰이더의 진입점을 이용해 파이프라인의 스테이지(stage)를 만들고, 파이프라인 레이아웃과 함께 컴퓨트 파이프라인을 만듭니다.
여기에서 DirectX와 Metal과 비교했을 때 Vulkan에만 존재하는 디스크립터라는 개념이 새롭게 등장합니다. 이 개념은 Vulkan을 어렵게 하는 원흉이기도 한데, 이 개념에 대해 조금 더 심층적으로 알아보겠습니다.
디스크립터와 디스크립터 셋, 그리고 디스크립터 셋 레이아웃의 멘탈 모델
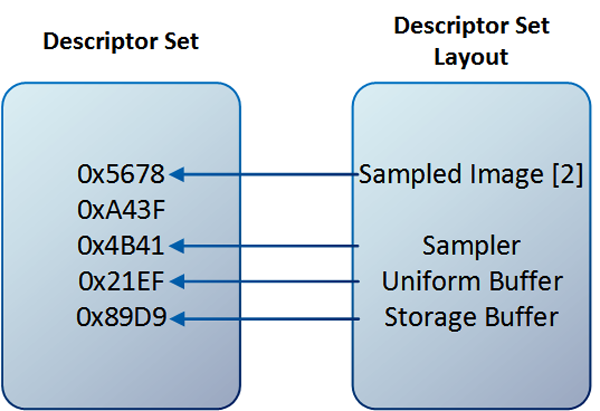 디스크립터 셋(descriptor set)과 디스크립터 셋 레이아웃(descriptor set layout)의 관계.
디스크립터 셋(descriptor set)과 디스크립터 셋 레이아웃(descriptor set layout)의 관계.
여기서 디스크립터 셋 내 5개의 16진수 표현 각각은 디스크립터(descriptor)가 가르키는 리소스의 포인터를 의미합니다.
Vulkan에서 파이프라인이 리소스를 사용하기 위해서는 그 리소스에 대한 참조가 필요합니다. 이러한 참조는 디스크립터(descriptor)를 통해 이루어집니다. 디스크립터를 이해하는 가장 쉬운 멘탈 모델은 어떤 리소스의 주소와 그 리소스에 대한 정보를 포함하는 “뚱뚱한 포인터(fat pointer)”입니다. 우리는 이 뚱뚱한 포인터를 파이프라인에 바인딩하여 파이프라인이 리소스에 접근할 수 있게 합니다. 지금은 버퍼 1개만을 예시로 들고 있으나, 이미지 뷰(image view)나 샘플러(sampler) 또한 바인딩 할 수 있습니다.
정확히 말하면, 디스크립터는 파이프라인이 아닌 파이프라인이 바인딩된 커맨드 버퍼에 바인딩하는 것입니다. 아직은 커맨드 버퍼를 설명하지 않았으니 일단 파이프라인에 바인딩 한다는 뜻을 “파이프라인이 디스크립터가 참조하는 리소스를 볼 수 있게 한다” 정도로 이해하시면 됩니다.
실제 게임을 만든다고 가정해봅시다. 우리가 렌더링해야 할 씬(scene)에는 수많은 3D 모델이 존재하고, 이 모델 각각에 대한 텍스쳐가 존재합니다. 낮게 어림잡아 약 100개의 모델과 모델 하나에 4개의 텍스쳐가 필요하여 총 400개의 텍스쳐가 필요하다고 가정합니다. 렌더 파이프라인에서 이 텍스쳐(Vulkan의 표현으로는 이미지)를 보려면 각각의 텍스쳐 리소스를 가르키는 디스크립터 400개를 만들고, 이를 파이프라인에 바인딩해야합니다. 그러나 400개를 한 프레임마다 일일이 바인딩하는 것은 Vulkan API를 400번 호출하겠다는 말이고, 이는 비합리적인 연산입니다. 특히, 디스크립터를 바인딩하는 것은 다른 드라이버 호출 작업과 비교했을 때에도 시간이 오래 걸리는 작업입니다.
이러한 문제를 해결하기 위해 디스크립터 셋이라는 개념이 도입되었습니다. 디스크립터 셋은 디스크립터의 묶음입니다. 하나의 디스크립터 셋이 여러 개의 디스크립터를 포함하고 있고, 이 디스크립터를 파이프라인에 바인딩할 수 있는 최소의 단위가 디스크립터 셋입니다 (마치 우리가 컴퓨트 셰이더에서 개개의 invocation을 실행할 수 없고 워크 그룹 단위로 실행해야 하는 것처럼 말이죠).
한 파이프라인에 바인딩할 수 있는 디스크립터 셋의 개수는 하드웨어 제원에 따라 다르나, Vulkan 명세가 보증하는 최소 개수는 오직 4개입니다. 앞서 설명했던 400개의 텍스쳐를 오직 4번의 디스크립터 셋 바인딩만을 이용하라니, 이게 대체 무슨 소리인건가 싶을 것입니다. 한 번 바인딩 할 때 100개 이상의 텍스쳐를 정해야 하는데, 어떤 상황에서는 그 100개의 텍스쳐가 쓰이지도 않을 것인데, 어떻게 바인딩 전략을 세울 수 있을까요?
이를 효율적으로 바인딩하는 방법은 바로 디스크립터를 그 업데이트 빈도에 따라 디스크립터 셋으로 묶는 것입니다. 한 프레임에서 어떤 리소스는 프레임 내내 사용되고 (예를 들어, 카메라의 시점 정보를 나타내는 정보), 어떤 리소스는 씬별로 사용될 것이며 (예: 모델의 주변 환경 텍스쳐), 어떤 리소스는 씬에 있는 각 모델마다 다르게 (예: 모델의 위치·크기·회전 등 변환 정보), 어떤 리소스는 하나의 모델에 속한 여러 개의 메시(mesh; 하나의 텍스쳐에 대응하는 모델의 정점 정보)마다 다르게 적용되어야 할 것입니다 (예: 메시 텍스쳐). 이처럼 서로 다른 업데이트 빈도를 갖는 이 리소스들을 각각 디스크립터 셋 #0, #1, #2, #3으로 나누고 필요할 때마다 업데이트하면 API 호출을 최소화하며 효율적으로 사용할 수 있습니다.
이제 디스크립터와 디스크립터 셋의 차이점을 알았으니, 마지막으로 디스크립터 셋 레이아웃은 무엇을까요? 앞서 설명한 디스크립터와 디스크립터 셋은 파이프라인에서 사용할 실제 리소스를 가르키는 객체입니다. 반면, 우리가 파이프라인을 만드는 지금 시점에서는 아직 실제 리소스가 존재하지 않아도 됩니다. 단지, 이 파이프라인이 사용할 리소스에 대한 정보, 즉 레이아웃만을 명시해주면 됩니다. 이 레이아웃 또한 마찬가지로 디스크립터를 바인딩할 수 있는 최소의 단위인 디스크립터 셋의 단위로 명시해야 합니다. 디스크립터 셋 레이아웃은 파이프라인에 바인딩된 디스크립터 셋의 개수와 같아야 합니다. 또 개개의 디스크립터 셋 레이아웃에는
- 어떤 종류의 디스크립터가 있는지,
- 그 디스크립터의 추가적 특성에는 무엇이 있는지 (이는 이미지 디스크립터에서 추가적으로 다룰 것입니다)
다음과 같은 정보를 명시함으로써 생성할 수 있습니다.
지금까지의 내용을 이번 목표에 도입하면, 우리는 단지 한 개의 버퍼만을 사용하기에 하나의 디스크립터 셋만이 있을 것이고, 이 디스크립터 셋에는 버퍼를 가르키는 하나의 버퍼 디스크립터가 있을 것입니다. 그리고 한 개의 디스크립터 셋에 대응하는 한 개의 파이프라인 디스크립터 셋 레이아웃이 있을 것입니다. 지금부터 이를 코드로 옮겨보겠습니다.
디스크립터 셋 레이아웃 생성하기
디스크립터 셋 레이아웃을 생성하기 위해서는 해당 셋에 속한 바인딩에 대한 정보를 나타내는 디스크립터 셋 레이아웃 바인딩 (descriptor set layout binding)을 만들어야 합니다. 하나의 디스크립터 셋 레이아웃 바인딩은 어떤 디스크립터 셋에 속한 디스크립터의
- 바인딩 인덱스
- 디스크립터 종류
- 해당 바인딩에 속한 디스크립터 개수
- 이 디스크립터가 사용될 셰이더 스테이지 (shader stage)
를 명시해야 합니다. 이를 코드로 확인해보겠습니다.
Subject: [PATCH] Create descriptor set layout.
---
Index: src/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/main.cpp b/src/main.cpp
--- a/src/main.cpp
+++ b/src/main.cpp
@@ -127,5 +127,19 @@
const std::span nums { static_cast<float*>(data), 1024 };
std::iota(nums.begin(), nums.end(), 0.f);
+ // Create descriptor set layout.
+ const vk::raii::DescriptorSetLayout descriptorSetLayout = [&] {
+ constexpr vk::DescriptorSetLayoutBinding layoutBinding {
+ 0,
+ vk::DescriptorType::eStorageBuffer,
+ 1,
+ vk::ShaderStageFlagBits::eCompute,
+ };
+ return vk::raii::DescriptorSetLayout { device, vk::DescriptorSetLayoutCreateInfo {
+ {},
+ layoutBinding,
+ } };
+ }();
+
(*device).unmapMemory(*bufferMemory);
}
\ No newline at end of file
vk::raii::DescriptorSetLayout 객체를 생성하기 위해 생성자의 첫 번째 인수로 디바이스를, 두 번째 인수로 생성 정보 구조체 vk::DescriptorSetLayoutCreateInfo를 넘겼는데, 이 구조체 생성자의 두 번째 인수는 vk::ArrayProxyNoTemporaries<const vk::DescriptorSetLayoutBinding> 타입으로 임시적이지 않은 vk::DescriptorSetLayoutBinding의 배열(또는 낱개)을 전달해야 함을 의미합니다. 따라서 layoutBinding이라는 상수 변수를 하나 만들고, 그 생성자에 바인딩 번호 (0), 디스크립터 타입 (eStorageBuffer: 우리가 만든 버퍼는 스토리지 버퍼로써 사용되어야 합니다), 디스크립터 개수 (1: 이 바인딩에는 하나의 디스크립터만이 존재함), 셰이더 스테이지 플래그 (eCompute: 이 바인딩은 컴퓨트 셰이더에서만 사용됩니다)를 순서대로 넘겼습니다.
세 번째 인수를 1로 넘김으로써 이 바인딩에 하나의 디스크립터만이 존재한다는 뜻은 무엇일까요? 사실 한 바인딩에는 여러 개의 디스크립터를 넘길 수 있습니다. 예를 들면 다음과 같이 0번째 디스크립터 셋의 0번째 바인딩에 8개의 이미지를 배열로 정의한다면
1
layout (set = 0, binding = 0) image2d textures[8]; // (0, 0) has 8 images, which can be accessed via subscript operator.
이 경우 디스크립터 타입을 eStorageImage (스토리지 이미지; 이는 다음 목표에서 다룹니다), 디스크립터 개수를 8로 전달할 수 있겠습니다.
컴퓨트 파이프라인에서 오직 1개의 디스크립터 셋만이 사용되므로, 디스크립터 셋 레이아웃 또한 한 개만 생성했음을 유의하세요. 두 개념은 일대일로 대응합니다.
파이프라인 레이아웃 생성하기
파이프라인 레이아웃은 디스크립터 셋과 더불어, push constant라는 파이프라인의 또다른 특성을 정의합니다. 하지만, 이번 목표에서는 push constant를 사용하지 않으므로 방금 전 생성한 descriptorSetLayout으로부터 바로 파이프라인 레이아웃이 생성될 수 있습니다.
Subject: [PATCH] Create pipeline layout.
---
Index: src/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/main.cpp b/src/main.cpp
--- a/src/main.cpp
+++ b/src/main.cpp
@@ -141,5 +141,11 @@
} };
}();
+ // Create pipeline layout.
+ const vk::raii::PipelineLayout pipelineLayout { device, vk::PipelineLayoutCreateInfo {
+ {},
+ *descriptorSetLayout,
+ } };
+
(*device).unmapMemory(*bufferMemory);
}
\ No newline at end of file
컴퓨트 파이프라인 생성하기
디스크립터 셋 레이아웃과 파이프라인 레이아웃을 생성했으므로 이제 컴퓨트 파이프라인을 생성할 수 있습니다. 컴퓨트 파이프라인을 생성하기 앞서 이전에 만든 컴퓨트 셰이더를 불러와 셰이더 모듈로 만들어야 합니다.
셰이더 모듈 생성하기
셰이더 모듈은 SPIR-V로 컴파일된 셰이더 코드로부터 생성될 수 있습니다. 먼저, 셰이더 코드를 바이너리 형태로 불러오는 함수 readFile을 작성해봅시다.
Subject: [PATCH] Add function that loads file data as binary.
---
Index: src/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/main.cpp b/src/main.cpp
--- a/src/main.cpp
+++ b/src/main.cpp
@@ -28,6 +28,22 @@
}
}
+[[nodiscard]] auto readFile(
+ const std::filesystem::path &path
+) -> std::vector<std::uint32_t> {
+ std::ifstream file { path, std::ios::ate | std::ios::binary };
+ if (!file.is_open()) {
+ throw std::runtime_error { "Failed to open file." };
+ }
+
+ const std::size_t fileSizeInBytes = file.tellg();
+ std::vector<std::uint32_t> buffer(fileSizeInBytes / sizeof(std::uint32_t));
+ file.seekg(0);
+ file.read(reinterpret_cast<char*>(buffer.data()), fileSizeInBytes);
+
+ return buffer;
+}
+
int main(){
const vk::raii::Context context{};
auto <함수명>(<함수 인수>...) -> <반환 타입>형태의 함수 선언은 C++11부터 지원되는 후위 반환 표기법입니다.
파일의 경로를 인수로 받아 해당 파일을 바이트 단위로 읽어 std::uint32_t의 벡터를 생성하는 readFile 함수는 먼저 파일을 std::ifstream으로 읽고, 해당 IO 객체의 tellg 메서드를 사용해 파일의 전체 바이트 크기를 불러옵니다. 불러온 크기를 바탕으로 buffer 벡터를 미리 할당함으로써, 파일을 읽는 동안 버퍼 오버플로우가 발생하여 메모리가 재할당되는 것을 막습니다. tellg() 메서드를 호출한 후 다시 seekg(0) 메서드를 호출하여 커서가 파일의 처음 위치로 와야 파일을 읽을 수 있음을 유의하세요.
이제 readFile 함수를 이용해 작성한 multiply.comp.spv 파일을 읽고, 셰이더 모듈을 생성해봅시다.
Subject: [PATCH] Create shader module from loaded shader code.
---
Index: src/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/main.cpp b/src/main.cpp
--- a/src/main.cpp
+++ b/src/main.cpp
@@ -163,5 +163,14 @@
*descriptorSetLayout,
} };
+ // Create compute shader module.
+ const vk::raii::ShaderModule computeShaderModule = [&] {
+ const std::vector shaderCode = readFile("shaders/multiply.comp.spv");
+ return vk::raii::ShaderModule { device, vk::ShaderModuleCreateInfo {
+ {},
+ shaderCode,
+ } };
+ }();
+
(*device).unmapMemory(*bufferMemory);
}
\ No newline at end of file
마찬가지로 vk::raii::ShaderModule 객체를 생성하기 위해 생성 정보에 셰이더 코드를 넣어 셰이더 모듈을 생성하였습니다.
파이프라인 생성하기
이제 이 모든 과정의 결과인 컴퓨트 파이프라인을 생성할 차례입니다. 컴퓨트 파이프라인은 컴퓨트 셰이더 모듈과 해당 셰이더의 진입점 (우리의 경우 main), 그리고 앞서 생성한 파이프라인 레이아웃을 전달하여 만들 수 있습니다.
Subject: [PATCH] Create compute pipeline.
---
Index: src/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/main.cpp b/src/main.cpp
--- a/src/main.cpp
+++ b/src/main.cpp
@@ -172,5 +172,17 @@
} };
}();
+ // Create compute pipeline.
+ const vk::raii::Pipeline computePipeline { device, nullptr, vk::ComputePipelineCreateInfo {
+ {},
+ vk::PipelineShaderStageCreateInfo {
+ {},
+ vk::ShaderStageFlagBits::eCompute,
+ *computeShaderModule,
+ "main",
+ },
+ *pipelineLayout,
+ } };
+
(*device).unmapMemory(*bufferMemory);
}
\ No newline at end of file
다른 RAII 객체들의 생성자들과 다른 점이 하나 발견되었습니다. 생성 정보 구조체는 (기존처럼 두 번째 인수가 아닌) 세 번째 인수로 전달되었고, 두 번째 인수에 nullptr을 전달했는데 이는 파이프라인 캐시 (pipeline cache)라는 것입니다. Vulkan에서 파이프라인을 생성하는 과정은 시간이 오래 걸리는 작업인데, 이 생성 작업은 GPU 드라이버에 실행 환경에 의존합니다. 즉, 만일 같은 드라이버와 실행 환경에서 생성된 실제 GPU 파이프라인 데이터는 사용자가 그 환경을 변화(예를 들면 드라이버나 운영체제를 업데이트하는 경우)하지 않는 한 같은 값을 가질 것이고, 따라서 이 경우 이전에 생성된 데이터를 그저 불러오는 것으로 파이프라인 생성을 대체할 수 있습니다. 이번 튜토리얼에서는 난이도를 위해 파이프라인 캐시는 사용하지 않겠습니다6.
마찬가지로 생성 정보 구조체에는 vk::PipelineShaderStageCreateInfo라는 셰이더 스테이지를 명시하였으며 이 셰이더가 컴퓨트 파이프라인에 사용될 것임을 명시하는 eCompute와 main 진입점 이름이 전달되었음을 확인할 수 있습니다 (당연히 컴퓨트 파이프라인을 만들기에 이 값은 다른 셰이더 스테이지가 사용될 수 없습니다).
코드 작성을 완료했다면 프로젝트를 실행한 후 검증 레이어가 오류를 출력하지 않음을 확인하세요.
참고로, 컴퓨트 파이프라인(과 더불어 뒤에 나올 그래픽 파이프라인을 포함하여)이 생성된 후 셰이더 모듈은 소멸해도 괜찮습니다. 즉, 다음과 같은 코드 또한 허용됩니다:
이번 튜토리얼의 전체 코드 변경 사항은 다음과 같습니다.
Subject: [PATCH] Create compute pipeline.
Create shader module from loaded shader code.
Add function that loads file data as binary.
Create pipeline layout.
Create descriptor set layout.
Add CMake scripts that compiles the given shader files.
Add compute shader that multiply 2 to the floats.
---
Index: src/shaders/multiply.comp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/shaders/multiply.comp b/src/shaders/multiply.comp
new file mode 100644
--- /dev/null
+++ b/src/shaders/multiply.comp
@@ -0,0 +1,10 @@
+#version 450
+
+layout (set = 0, binding = 0) buffer Ssbo { float data[]; };
+
+layout (local_size_x = 256) in;
+
+void main(){
+ uint index = gl_GlobalInvocationID.x;
+ data[index] *= 2.0;
+}
\ No newline at end of file
Index: src/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/CMakeLists.txt b/src/CMakeLists.txt
--- a/src/CMakeLists.txt
+++ b/src/CMakeLists.txt
@@ -32,4 +32,13 @@
# --------------------
add_executable(vulkan-tutorial main.cpp)
-target_link_libraries(vulkan-tutorial PRIVATE VulkanHppModule)
\ No newline at end of file
+target_link_libraries(vulkan-tutorial PRIVATE VulkanHppModule)
+
+# --------------------
+# Compile shaders.
+# --------------------
+
+include(cmake/CompileShader.cmake)
+compile_shaders(vulkan-tutorial
+ shaders/multiply.comp
+)
\ No newline at end of file
Index: src/cmake/CompileShader.cmake
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/cmake/CompileShader.cmake b/src/cmake/CompileShader.cmake
new file mode 100644
--- /dev/null
+++ b/src/cmake/CompileShader.cmake
@@ -0,0 +1,28 @@
+# Compile shader files and copy them into build directory.
+#
+# Usage:
+# compile_shaders(target
+# path1/shader1.vert
+# path2/shader2.frag
+# ...
+# )
+#
+# Result: path1/shader1.vert.spv, path2/shader2.frag.spv, ... in build directory.
+
+find_package(Vulkan COMPONENTS glslc REQUIRED)
+find_program(glslc_executable NAMES glslc HINTS Vulkan::glslc)
+
+function(compile_shaders target)
+ # Get the rest of the arguments after the target name
+ set(sources ${ARGN})
+
+ foreach(source ${sources})
+ add_custom_command(
+ OUTPUT ${CMAKE_CURRENT_BINARY_DIR}/${source}.spv
+ DEPENDS ${CMAKE_CURRENT_SOURCE_DIR}/${source}
+ DEPFILE ${CMAKE_CURRENT_SOURCE_DIR}/${source}.d
+ COMMAND ${glslc_executable} ${CMAKE_CURRENT_SOURCE_DIR}/${source} -o ${CMAKE_CURRENT_BINARY_DIR}/${source}.spv
+ )
+ target_sources(${target} PRIVATE ${CMAKE_CURRENT_BINARY_DIR}/${source}.spv)
+ endforeach()
+endfunction()
\ No newline at end of file
Index: src/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/main.cpp b/src/main.cpp
--- a/src/main.cpp
+++ b/src/main.cpp
@@ -28,6 +28,22 @@
}
}
+[[nodiscard]] auto readFile(
+ const std::filesystem::path &path
+) -> std::vector<std::uint32_t> {
+ std::ifstream file { path, std::ios::ate | std::ios::binary };
+ if (!file.is_open()) {
+ throw std::runtime_error { "Failed to open file." };
+ }
+
+ const std::size_t fileSizeInBytes = file.tellg();
+ std::vector<std::uint32_t> buffer(fileSizeInBytes / sizeof(std::uint32_t));
+ file.seekg(0);
+ file.read(reinterpret_cast<char*>(buffer.data()), fileSizeInBytes);
+
+ return buffer;
+}
+
int main(){
const vk::raii::Context context{};
@@ -127,5 +143,46 @@
const std::span nums { static_cast<float*>(data), 1024 };
std::iota(nums.begin(), nums.end(), 0.f);
+ // Create descriptor set layout.
+ const vk::raii::DescriptorSetLayout descriptorSetLayout = [&] {
+ constexpr vk::DescriptorSetLayoutBinding layoutBinding {
+ 0,
+ vk::DescriptorType::eStorageBuffer,
+ 1,
+ vk::ShaderStageFlagBits::eCompute,
+ };
+ return vk::raii::DescriptorSetLayout { device, vk::DescriptorSetLayoutCreateInfo {
+ {},
+ layoutBinding,
+ } };
+ }();
+
+ // Create pipeline layout.
+ const vk::raii::PipelineLayout pipelineLayout { device, vk::PipelineLayoutCreateInfo {
+ {},
+ *descriptorSetLayout,
+ } };
+
+ // Create compute shader module.
+ const vk::raii::ShaderModule computeShaderModule = [&] {
+ const std::vector shaderCode = readFile("shaders/multiply.comp.spv");
+ return vk::raii::ShaderModule { device, vk::ShaderModuleCreateInfo {
+ {},
+ shaderCode,
+ } };
+ }();
+
+ // Create compute pipeline.
+ const vk::raii::Pipeline computePipeline { device, nullptr, vk::ComputePipelineCreateInfo {
+ {},
+ vk::PipelineShaderStageCreateInfo {
+ {},
+ vk::ShaderStageFlagBits::eCompute,
+ *computeShaderModule,
+ "main",
+ },
+ *pipelineLayout,
+ } };
+
(*device).unmapMemory(*bufferMemory);
}
\ No newline at end of file
RTX 4090은 18,000개의 CUDA 코어를 탑재하고 있습니다. 참고로 CPU중 가장 많은 코어 수를 자랑하는 AMD RYZEN Threadripper는 64개의 코어를 탑재하고 있습니다. ↩
barrier()및memoryBarrierShared()함수. OpenGL 명세의 Shared memory coherency 섹션을 참조하세요. ↩https://developer.nvidia.com/blog/advanced-api-performance-intrinsics/ ↩
관례입니다. ↩
견고한 파이프라인 캐시 생성을 위한 방법이라는 좋은 글이 있으니 관심있는 분들은 찾아보시기 바랍니다. ↩