Vulkan 튜토리얼: 이미지와 이미지 뷰 생성하기
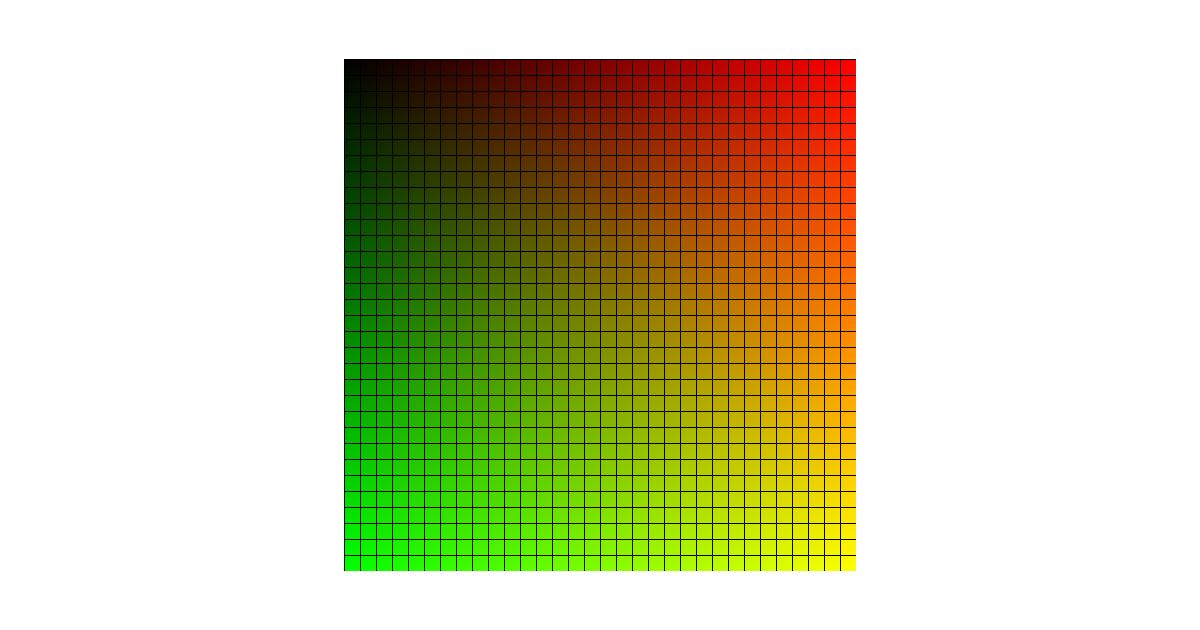
안녕하세요, 지난 번 튜토리얼에서 예고했듯 이번에는 새로운 소주제를 시작해보겠습니다. 이번 소주제의 주제는 바로 우리가 볼 수 있는 “이미지”입니다. 이제 본격적으로 Vulkan의 그래픽스 API적 면모를 볼 수 있겠군요.
사실 Vulkan에서 이미지를 바라보는 관점은 버퍼와 비슷합니다. 이 둘은 결국 바이트 데이터를 소유하는 디바이스 메모리를 가르키는 객체라는 점에서 동등하며, 단지 이 데이터를 어떻게 취급하는지에 따라 다르게 쓰일 뿐입니다.
물론 완전히 같은 것만은 아닙니다. 이미지가 가지는 데이터는 버퍼보다 더 구조화돼있고, Vulkan은 다양한 환경과 용도에서 이미지를 사용할 수 있게 하기 위해 이미지의 크기 단위로 3차원 벡터를 사용하며, 레이어(layer)와 밉 레벨(mip level)이라는 이미지의 특정 리소스를 가르킬 수 있는 개념이 있습니다. 또한 이미지는 사용 용도에 맞게 특정 시점에 레이아웃(layout)을 가질 수 있으며, 버퍼와 달리 이를 명시적으로 추적해야 합니다.
이번 튜토리얼에서는 이미지당 오직 한 개의 레이어와 밉 레벨만을 갖기 때문에, 일단은 쉬운 접근으로 시작하도록 하겠습니다.
이번 튜토리얼에서는…
우리는 지난번과 마찬가지로 컴퓨트 셰이더를 이용해 위와 같은 그래디언트를 갖는 격자 이미지를 생성할 것입니다. 아직은 화면에 이미지를 출력할 수 없으므로, 이미지는 실행 파일이 속한 디렉터리에 이미지 파일 형식으로 저장합니다.
같은 CMake 프로젝트 내 여러 개의 튜토리얼 예제를 만들기 위해 프로젝트 구조를 조금 변경하겠습니다. 지난번 튜토리얼의 CMake 타겟 이름 vulkan-tutorial을 01_buffer-multiply로 변경하고, 동일한 파일을 갖는 새 타겟 02_compute-image를 추가하겠습니다.
Subject: [PATCH] Restructured directories and add new target 02_compute-image.
---
Index: src/01_buffer-multiply/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/01_buffer-multiply/CMakeLists.txt b/src/01_buffer-multiply/CMakeLists.txt
new file mode 100644
--- /dev/null
+++ b/src/01_buffer-multiply/CMakeLists.txt
@@ -0,0 +1,14 @@
+# --------------------
+# Project executables.
+# --------------------
+
+add_executable(01_buffer-multiply main.cpp)
+target_link_libraries(01_buffer-multiply PRIVATE VulkanHppModule)
+
+# --------------------
+# Compile shaders.
+# --------------------
+
+compile_shaders(01_buffer-multiply
+ shaders/multiply.comp
+)
\ No newline at end of file
Index: src/02_compute-image/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/CMakeLists.txt b/src/02_compute-image/CMakeLists.txt
new file mode 100644
--- /dev/null
+++ b/src/02_compute-image/CMakeLists.txt
@@ -0,0 +1,14 @@
+# --------------------
+# Project executables.
+# --------------------
+
+add_executable(02_compute-image main.cpp)
+target_link_libraries(02_compute-image PRIVATE VulkanHppModule)
+
+# --------------------
+# Compile shaders.
+# --------------------
+
+compile_shaders(02_compute-image
+ shaders/multiply.comp
+)
\ No newline at end of file
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
new file mode 100644
--- /dev/null
+++ b/src/02_compute-image/main.cpp
@@ -0,0 +1,256 @@
+#include <cassert>
+
+import std;
+import vulkan_hpp;
+
+#define FWD(...) static_cast<decltype(__VA_ARGS__)&&>(__VA_ARGS__)
+
+namespace std::ranges {
+ template <typename Derived>
+ struct range_adaptor_closure {
+ template <std::ranges::range R>
+ friend constexpr auto operator|(
+ R &&r,
+ const Derived &self
+ ) noexcept(std::is_nothrow_invocable_v<const Derived&, R>) -> auto {
+ return self(FWD(r));
+ }
+ };
+
+namespace views {
+ struct enumerate_fn : range_adaptor_closure<enumerate_fn> {
+ static constexpr auto operator()(
+ std::ranges::input_range auto &&r
+ ) -> auto {
+ return zip(iota(std::int64_t { 0 }), FWD(r));
+ }
+ };
+
+ constexpr enumerate_fn enumerate;
+}
+}
+
+[[nodiscard]] auto readFile(
+ const std::filesystem::path &path
+) -> std::vector<std::uint32_t> {
+ std::ifstream file { path, std::ios::ate | std::ios::binary };
+ if (!file.is_open()) {
+ throw std::runtime_error { "Failed to open file." };
+ }
+
+ const std::size_t fileSizeInBytes = file.tellg();
+ std::vector<std::uint32_t> buffer(fileSizeInBytes / sizeof(std::uint32_t));
+ file.seekg(0);
+ file.read(reinterpret_cast<char*>(buffer.data()), fileSizeInBytes);
+
+ return buffer;
+}
+
+int main(){
+ const vk::raii::Context context{};
+
+ const vk::raii::Instance instance = [&] {
+ constexpr vk::ApplicationInfo appInfo {
+ "Vulkan tutorial", {},
+ {}, {},
+ vk::makeApiVersion(0, 1, 0, 0), // Vulkan 1.0.
+ };
+ const std::vector<const char*> instanceLayers {
+#ifndef NDEBUG
+ "VK_LAYER_KHRONOS_validation",
+#endif
+ };
+ const std::vector<const char*> instanceExtensions {
+#if __APPLE__
+ "VK_KHR_portability_enumeration",
+ "VK_KHR_get_physical_device_properties2",
+#endif
+ };
+ return vk::raii::Instance { context, vk::InstanceCreateInfo {
+#if __APPLE__
+ vk::InstanceCreateFlagBits::eEnumeratePortabilityKHR,
+#else
+ {},
+#endif
+ &appInfo,
+ instanceLayers,
+ instanceExtensions,
+ } };
+ }();
+
+ const vk::raii::PhysicalDevice physicalDevice = instance.enumeratePhysicalDevices().front();
+
+ const std::uint32_t computeQueueFamilyIndex = [&] {
+ for (auto [idx, properties] : physicalDevice.getQueueFamilyProperties() | std::views::enumerate) {
+ if (properties.queueFlags & vk::QueueFlagBits::eCompute) {
+ return idx;
+ }
+ }
+
+ // Since Vulkan specifies that a compute queue must be present, this should never happen.
+ throw std::runtime_error { "No compute queue family in the physical device." };
+ }();
+
+ const vk::raii::Device device = [&] {
+ constexpr std::array queuePriorities { 1.f };
+ const vk::DeviceQueueCreateInfo queueCreateInfo {
+ {},
+ computeQueueFamilyIndex,
+ queuePriorities,
+ };
+ const std::vector<const char*> deviceExtensions {
+#if __APPLE__
+ "VK_KHR_portability_subset",
+#endif
+ };
+ return vk::raii::Device { physicalDevice, vk::DeviceCreateInfo {
+ {},
+ queueCreateInfo,
+ {},
+ deviceExtensions,
+ } };
+ }();
+
+ const vk::Queue computeQueue = (*device).getQueue(computeQueueFamilyIndex, 0);
+
+ const vk::raii::Buffer buffer { device, vk::BufferCreateInfo {
+ {},
+ sizeof(float) * 1024,
+ vk::BufferUsageFlagBits::eStorageBuffer,
+ } };
+
+ const auto getMemoryTypeIndex
+ = [memoryTypes = physicalDevice.getMemoryProperties().memoryTypes](
+ vk::MemoryPropertyFlags memoryPropertyFlags
+ ) -> std::uint32_t {
+ for (auto [idx, memoryType] : memoryTypes | std::views::enumerate) {
+ if ((memoryType.propertyFlags & memoryPropertyFlags) == memoryPropertyFlags) {
+ return idx;
+ }
+ }
+
+ throw std::runtime_error { "No suitable memory type found." };
+ };
+
+ const vk::raii::DeviceMemory bufferMemory { device, vk::MemoryAllocateInfo {
+ buffer.getMemoryRequirements().size,
+ getMemoryTypeIndex(vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent),
+ } };
+ buffer.bindMemory(*bufferMemory, 0);
+
+ // Map whole ranges of bufferMemory into host memory.
+ void* const data = (*device).mapMemory(*bufferMemory, 0, vk::WholeSize);
+
+ // Fill buffer with floats from 0 to 1023.
+ const std::span nums { static_cast<float*>(data), 1024 };
+ std::iota(nums.begin(), nums.end(), 0.f);
+
+ // Create descriptor set layout.
+ const vk::raii::DescriptorSetLayout descriptorSetLayout = [&] {
+ constexpr vk::DescriptorSetLayoutBinding layoutBinding {
+ 0,
+ vk::DescriptorType::eStorageBuffer,
+ 1,
+ vk::ShaderStageFlagBits::eCompute,
+ };
+ return vk::raii::DescriptorSetLayout { device, vk::DescriptorSetLayoutCreateInfo {
+ {},
+ layoutBinding,
+ } };
+ }();
+
+ // Create pipeline layout.
+ const vk::raii::PipelineLayout pipelineLayout { device, vk::PipelineLayoutCreateInfo {
+ {},
+ *descriptorSetLayout,
+ } };
+
+ // Create compute shader module.
+ const vk::raii::ShaderModule computeShaderModule = [&] {
+ const std::vector shaderCode = readFile("shaders/multiply.comp.spv");
+ return vk::raii::ShaderModule { device, vk::ShaderModuleCreateInfo {
+ {},
+ shaderCode,
+ } };
+ }();
+
+ // Create compute pipeline.
+ const vk::raii::Pipeline computePipeline { device, nullptr, vk::ComputePipelineCreateInfo {
+ {},
+ vk::PipelineShaderStageCreateInfo {
+ {},
+ vk::ShaderStageFlagBits::eCompute,
+ *computeShaderModule,
+ "main",
+ },
+ *pipelineLayout,
+ } };
+
+ // Create descriptor pool.
+ const vk::raii::DescriptorPool descriptorPool = [&] {
+ constexpr vk::DescriptorPoolSize poolSize {
+ vk::DescriptorType::eStorageBuffer,
+ 1,
+ };
+ return vk::raii::DescriptorPool { device, vk::DescriptorPoolCreateInfo {
+ {},
+ 1,
+ poolSize,
+ } };
+ }();
+
+ // Allocate descriptor set from descriptor pool.
+ const vk::DescriptorSet descriptorSet = (*device).allocateDescriptorSets(vk::DescriptorSetAllocateInfo {
+ *descriptorPool,
+ *descriptorSetLayout,
+ }).front();
+
+ // Write buffer info to descriptorSet.
+ const vk::DescriptorBufferInfo bufferInfo {
+ *buffer,
+ 0,
+ vk::WholeSize,
+ };
+ (*device).updateDescriptorSets(vk::WriteDescriptorSet {
+ descriptorSet,
+ 0,
+ 0,
+ vk::DescriptorType::eStorageBuffer,
+ {},
+ bufferInfo,
+ }, {});
+
+ // Create command pool.
+ const vk::raii::CommandPool commandPool { device, vk::CommandPoolCreateInfo {
+ {},
+ computeQueueFamilyIndex,
+ } };
+
+ // Allocate command buffer from commandPool.
+ const vk::CommandBuffer commandBuffer = (*device).allocateCommandBuffers(vk::CommandBufferAllocateInfo {
+ *commandPool,
+ vk::CommandBufferLevel::ePrimary,
+ 1,
+ }).front();
+
+ // Record commands that invoke computePipeline.
+ commandBuffer.begin({ vk::CommandBufferUsageFlagBits::eOneTimeSubmit });
+ commandBuffer.bindPipeline(vk::PipelineBindPoint::eCompute, *computePipeline);
+ commandBuffer.bindDescriptorSets(vk::PipelineBindPoint::eCompute, *pipelineLayout, 0, descriptorSet, {});
+ commandBuffer.dispatch(1024 / 256, 1, 1);
+ commandBuffer.end();
+
+ // Submit commandBuffer to computeQueue and wait for it to finish.
+ computeQueue.submit(vk::SubmitInfo {
+ {},
+ {},
+ commandBuffer,
+ });
+ computeQueue.waitIdle();
+
+ // Check if the result is correct.
+ constexpr auto expected = std::views::iota(0, 1024) | std::views::transform([](float x) { return x * 2.f; });
+ assert(std::ranges::equal(nums, expected) && "Unexpected result.");
+
+ (*device).unmapMemory(*bufferMemory);
+}
\ No newline at end of file
Index: src/02_compute-image/shaders/multiply.comp
===================================================================
diff --git a/src/02_compute-image/shaders/multiply.comp b/src/02_compute-image/shaders/multiply.comp
new file mode 100644
--- /dev/null
+++ b/src/02_compute-image/shaders/multiply.comp
@@ -0,0 +1,10 @@
+#version 450
+
+layout (set = 0, binding = 0) buffer Ssbo { float data[]; };
+
+layout (local_size_x = 256) in;
+
+void main(){
+ uint index = gl_GlobalInvocationID.x;
+ data[index] *= 2.0;
+}
\ No newline at end of file
Index: src/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/CMakeLists.txt b/src/CMakeLists.txt
--- a/src/CMakeLists.txt
+++ b/src/CMakeLists.txt
@@ -12,6 +12,12 @@
)
include(${CMAKE_BINARY_DIR}/EnableStandardLibraryModule.cmake)
+# --------------------
+# Include CMake scripts.
+# --------------------
+
+include(cmake/CompileShader.cmake)
+
# --------------------
# External dependencies.
# --------------------
@@ -28,17 +34,8 @@
include(${PROJECT_BINARY_DIR}/Vulkan.cmake)
# --------------------
-# Project executables.
-# --------------------
-
-add_executable(vulkan-tutorial main.cpp)
-target_link_libraries(vulkan-tutorial PRIVATE VulkanHppModule)
-
-# --------------------
-# Compile shaders.
+# Subdirectories.
# --------------------
-include(cmake/CompileShader.cmake)
-compile_shaders(vulkan-tutorial
- shaders/multiply.comp
-)
\ No newline at end of file
+add_subdirectory(01_buffer-multiply)
+add_subdirectory(02_compute-image)
\ No newline at end of file
diff --git a/src/main.cpp b/src/01_buffer-multiply/main.cpp
rename from src/main.cpp
rename to src/01_buffer-multiply/main.cpp
diff --git a/src/shaders/multiply.comp b/src/01_buffer-multiply/shaders/multiply.comp
rename from src/shaders/multiply.comp
rename to src/01_buffer-multiply/shaders/multiply.comp
또한, 이번 프로젝트에서는 getMemoryTypeIndex 람다를 물리 디바이스 선언부 이후로 옮기겠습니다. (이 람다는 전적으로 물리 디바이스의 성질을 이용하기 때문이죠!)
Subject: [PATCH] Move getMemoryTypeIndex function right below to the physical device declaration (this function is depend on physical device property)
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -80,6 +80,19 @@
const vk::raii::PhysicalDevice physicalDevice = instance.enumeratePhysicalDevices().front();
+ const auto getMemoryTypeIndex
+ = [memoryTypes = physicalDevice.getMemoryProperties().memoryTypes](
+ vk::MemoryPropertyFlags memoryPropertyFlags
+ ) -> std::uint32_t {
+ for (auto [idx, memoryType] : memoryTypes | std::views::enumerate) {
+ if ((memoryType.propertyFlags & memoryPropertyFlags) == memoryPropertyFlags) {
+ return idx;
+ }
+ }
+
+ throw std::runtime_error { "No suitable memory type found." };
+ };
+
const std::uint32_t computeQueueFamilyIndex = [&] {
for (auto [idx, properties] : physicalDevice.getQueueFamilyProperties() | std::views::enumerate) {
if (properties.queueFlags & vk::QueueFlagBits::eCompute) {
@@ -119,19 +132,6 @@
vk::BufferUsageFlagBits::eStorageBuffer,
} };
- const auto getMemoryTypeIndex
- = [memoryTypes = physicalDevice.getMemoryProperties().memoryTypes](
- vk::MemoryPropertyFlags memoryPropertyFlags
- ) -> std::uint32_t {
- for (auto [idx, memoryType] : memoryTypes | std::views::enumerate) {
- if ((memoryType.propertyFlags & memoryPropertyFlags) == memoryPropertyFlags) {
- return idx;
- }
- }
-
- throw std::runtime_error { "No suitable memory type found." };
- };
-
const vk::raii::DeviceMemory bufferMemory { device, vk::MemoryAllocateInfo {
buffer.getMemoryRequirements().size,
getMemoryTypeIndex(vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent),
이미지 생성하기
Vulkan의 버퍼가 vk::raii::Buffer인 것에서 유추하면, 이미지는 vk::raii::Image일 것입니다. 마찬가지로 디바이스와 이미지 생성 정보 구조체 vk::ImageCreateInfo를 생성자의 인수로 넘길 것이고, 이에 해당하는 디바이스 메모리를 만들어 바인딩하는 과정까지는 동일할 것입니다. R8G8B8A8_UNORM 형식(format)의 512x512 이미지를 생성해보겠습니다.
Subject: [PATCH] Create image that to be processed by compute shader.
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -126,24 +126,23 @@
const vk::Queue computeQueue = (*device).getQueue(computeQueueFamilyIndex, 0);
- const vk::raii::Buffer buffer { device, vk::BufferCreateInfo {
+ // Create image that to be processed by compute shader.
+ const vk::raii::Image image { device, vk::ImageCreateInfo {
{},
- sizeof(float) * 1024,
- vk::BufferUsageFlagBits::eStorageBuffer,
+ vk::ImageType::e2D,
+ vk::Format::eR8G8B8A8Unorm,
+ { 512, 512, 1 },
+ 1, 1,
+ vk::SampleCountFlagBits::e1,
+ vk::ImageTiling::eOptimal,
+ vk::ImageUsageFlagBits::eStorage,
} };
- const vk::raii::DeviceMemory bufferMemory { device, vk::MemoryAllocateInfo {
- buffer.getMemoryRequirements().size,
- getMemoryTypeIndex(vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent),
+ const vk::raii::DeviceMemory imageMemory { device, vk::MemoryAllocateInfo {
+ image.getMemoryRequirements().size,
+ getMemoryTypeIndex(vk::MemoryPropertyFlagBits::eDeviceLocal),
} };
- buffer.bindMemory(*bufferMemory, 0);
-
- // Map whole ranges of bufferMemory into host memory.
- void* const data = (*device).mapMemory(*bufferMemory, 0, vk::WholeSize);
-
- // Fill buffer with floats from 0 to 1023.
- const std::span nums { static_cast<float*>(data), 1024 };
- std::iota(nums.begin(), nums.end(), 0.f);
+ image.bindMemory(*imageMemory, 0);
// Create descriptor set layout.
const vk::raii::DescriptorSetLayout descriptorSetLayout = [&] {
@@ -247,10 +246,4 @@
commandBuffer,
});
computeQueue.waitIdle();
-
- // Check if the result is correct.
- constexpr auto expected = std::views::iota(0, 1024) | std::views::transform([](float x) { return x * 2.f; });
- assert(std::ranges::equal(nums, expected) && "Unexpected result.");
-
- (*device).unmapMemory(*bufferMemory);
}
\ No newline at end of file
버퍼 생성 정보 구조체에 비해 이미지는 뭐가 좀 많네요! 각 인수에 대해 정리해보겠습니다.
flags: 이미지 생성 플래그입니다. 아직은 쓸 일이 없으니 기본값으로 전달합니다.imageType: 생성할 이미지의 타입으로,vk::ImageType열거형을 사용합니다. 이 이미지가 1차원/2차원/3차원/또는 이들의 배열인지를 나타냅니다. 2차원 이미지를 생성할 것이므로e2D를 전달합니다.format: 이미지의 픽셀 형식입니다.vk::Format열거형을 사용하며, 여기서는R8G8B8A8_UNORM을 사용합니다.- 이 형식의 앞 R8G8B8A8은 한 텍셀(texel)이 네 개의 채널(R, G, B, A)를 가지며 각 채널이 8비트임을 의미합니다. 또한 뒤 UNORM은 각 채널의 표현 범위가 [0, 1]까지의 부호없는(unsigned; U에 대응) 부동소수점 수로 정규화(normalized; NORM에 대응)되어 있다는 것을 의미합니다.
- Vulkan에는 이미지에 사용할 수 있는 여러가지 형식이 있습니다. VulkanCapsViewer를 열고 Format 탭을 눌러 가용 이미지 형식을 확인하세요. 이들은 대개 (한 텍셀의 채널 및 바이트)_(채널별 표현 범위)의 이름을 갖습니다. 예를 들어,
R16G16_SINT는 두 채널(R, G)가 각각 부호 있는 16비트 정수로 표현됨을 의미합니다. - 어떤 형식에는
SRGB접미사가 붙는 것을 볼수 있습니다. 이러한 형식은 이미지의 픽셀에 읽기-쓰기 연산을 할 때 자동으로 감마 보정 (gamma correction)을 적용합니다. 이에 대해서는 향후 스왑체인을 다루면서 보다 자세히 설명하겠습니다.
extent: 이미지의 크기입니다. 이미지의 (너비, 높이, 깊이)를vk::Extent3D타입으로 전달해야 하며, 2차원 이미지의 경우 깊이를 1로 설정하여 전달합니다 (마찬가지로 1차원 이미지라면 높이와 깊이 모두 1로 설정해야겠지요).mipLevels: 이미지의 밉 레벨 수입니다. 밉 레벨은 본 이미지를 점층적으로 절반 크기로 축소하며 만든 이미지들로, 예를 들어 원래의 extent가 512x512라면 밉 레벨 1은 256x256, 밉 레벨 2는 128x128, …과 같이 만들어집니다. 이번 튜토리얼에서는 밉 레벨을 사용하지 않을 것이므로 1로 설정합니다.arrayLayers: 이미지 배열의 레이어 수입니다. 어떤 이미지의 extent가 512x512라면arrayLayers를 3으로 설정한다면 해당 이미지가 총 3개 만들어집니다. 이번 튜토리얼에서는 이미지 배열을 사용하지 않을 것이므로 1로 설정합니다.samples: 이미지에 MSAA(multisample anti-aliasing)를 적용할 경우 사용할 샘플 수로vk::SampleCountFlagBits열거형 인수입니다. 이미지가 어태치먼트(attachment)로 사용될 때만 유의합니다. 지금은 이미지를 어태치먼트로 사용하지 않으므로 기본값인e1(픽셀 한 개당 한 개의 샘플 사용)을 전달합니다.tiling: 이미지의 각 텍셀이 메모리에 어떻게 배치되는지를 정하며,vk::ImageTiling열거형 인수입니다. 다음 두 가지 선택지가 있습니다:vk::ImageTiling::eLinear: 텍셀은 행-우선 (row major)하게 연속적으로 저장됩니다. 예를 들어, 어떤 이미지의 1행 1열 텍셀이 (1.0, 0.5, 0.2, 1.0)이고 1행 2열 텍셀이 (0.8, 0.4, 0.8, 1.0)이라면 이 인수를 사용할 경우 이미지에 바인딩된 디바이스메모리는 실제 다음과 같은 데이터를 가질 것입니다:1
1.0, 0.5, 0.2, 1.0, 0.8, 0.4, 0.8, 1.0, ...
vk::ImageTiling::eOptimal: 텍셀이 GPU에 최적화된 방식으로 메모리에 저장됩니다. 이 인수를 사용할 경우 이미지는 GPU가 원하는 방식으로 빠르게 연산할 수 있지만, 그 메모리 레이아웃이 선형임을 보장하지 않습니다. 즉, 우리가 이 이미지의 특정 위치 $(i, j)$의 픽셀을 읽기 위해 디바이스 메모리를 매핑하여,data[width * i + j]로 읽을 수 없음을 의미합니다.- 대개 Vulkan에서 많은 경우 이미지 타일링은
eOptimal을 사용합니다.eLinear인수는 제약이 많습니다 (밉 레벨과 레이어 개수가 1로 제한되며, 지원하는 텍셀 형식이eOptimal과 비교했을 때 현저히 적습니다). 하지만 만일 호스트의 이미지 텍셀 데이터를 Vulkan의 이미지로 사용하려 할 경우, 먼저 이 텍셀 데이터를 디바이스 메모리를 매핑하여 선형 타일링 이미지에 저장한 후, 이 이미지로부터 최적 타일링 이미지로 복사하여 GPU에서 이미지를 사용할 수 있게 하는 스테이징(staging) 과정이 필요합니다.
usage: 이미지의 사용 용도를 나타내며,vk::ImageUsageFlags열거형 인수입니다. 이미지가 어떤 목적으로 사용될지를 나타내며, 여러 가지 플래그를 비트 OR 연산자로 결합하여 전달할 수 있습니다. 이번 튜토리얼에서는 이미지를 컴퓨트 셰이더에서 읽고 쓸 것이므로eStorage플래그를 전달합니다.
이미지가 버퍼보다 가지는 정보가 더 많으니, 더 많은 인수를 전달하는 것이 많습니다. 처음에는 이러한 여러 가지 개념이 복잡할 수 있으니, 일단은 형식(format)과 크기(extent), 타일링(tiling), 용도(usage)만을 중점적으로 이해해보시기 바랍니다.
3차원 이미지에 대해, extent의 깊이 성분과 레이어 개수는 다른 의미를 갖습니다. 마찬가지로 밉 레벨과 레이어 또한 배타적인 개념이 아니며 어떤 이미지는 밉 레벨과 여러 개의 레이어를 동시에 가질 수 있습니다.
이미지가 네 개의 밉 레벨과 세 개의 레이어를 가짐을 도표로 나타낸 모습.
이번에는 지금 이미지를 호스트에서 바로 읽지 않을 것이니 (앞서 말했듯 최적 타일링을 사용하므로 호스트에서는 이를 텍셀 형태로 읽고 쓸 수 없습니다) vk::MemoryPropertyFlagBits::eDeviceLocal을 사용해 디바이스에 최적화된 메모리를 사용하겠습니다. main 함수 마지막의 데이터 비교는 삭제하였습니다.
이미지 뷰 (image view) 생성하기
이제 이미지를 만들었으니 남은 과정은 이전과 같이 디스크립터 셋에 이미지 정보를 기록하고, 셰이더 코드의 디스크립터 셋 레이아웃을 이미지로 설정하여 조작하면 될 것 같습니다…만, 아직 한 가지 과정이 더 필요합니다. 바로 이미지 뷰(image view)를 생성하는 것입니다.
지금은 비록 생성했던 이미지가 한 개의 레이어와 밉 레벨만을 가지지만, 실제 이미지가 여러 개의 레이어와 밉 레벨을 가질 경우 이를 셰이더에서 사용할 때 특정 레이어와 밉 레벨만을 사용하고 싶을 때도 있을 것입니다. 또한, (흔하지 않은 경우이나) 이미지의 원래 형식과 달리 그 이미지에 텍셀을 읽고 쓰는 경우의 연산 방법에 임의의 형식을 쓰고 싶은 경우도 있습니다1.
이러한 여러 가지 사용 방법을 위해, Vulkan은 이미지 뷰를 도입했습니다. 이미지 뷰는 이미지에 대한 참조를 가지며, 해당 이미지의 리소스 중 어떤 범위의 것을 사용할 지에 대해 설정할 수 있습니다.
Subject: [PATCH] Create image view for image[mipLevel=0, arrayLayer=0].
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -144,6 +144,16 @@
} };
image.bindMemory(*imageMemory, 0);
+ // Create image view for image[mipLevel=0, arrayLayer=0].
+ const vk::raii::ImageView imageView { device, vk::ImageViewCreateInfo {
+ {},
+ *image,
+ vk::ImageViewType::e2D,
+ vk::Format::eR8G8B8A8Unorm,
+ {},
+ vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
+ } };
+
// Create descriptor set layout.
const vk::raii::DescriptorSetLayout descriptorSetLayout = [&] {
constexpr vk::DescriptorSetLayoutBinding layoutBinding {
vk::ImageViewCreateInfo 생성자의 정보로는 다음이 전달됩니다:
flags: 이미지 뷰 플래그. 지금은 기본 인수를 전달합니다.image: 이미지 뷰가 참조할 이미지입니다.viewType: 이미지 뷰의 타입. 이는 실제 셰이더에서 이미지를 어떻게 해석할 지에 대한 정보를 제공합니다. 우리는 2D 이미지를 사용하므로e2D를 전달합니다.format: 이미지 뷰의 형식. 대개 이는 이미지의 형식과 동일하나, 이미지의 텍셀 읽기/쓰기 방식을 달리하고 싶을 때 다른 형식을 사용할 수 있습니다1.components: 이미지 뷰의 컴포넌트 매핑 정보입니다. 이는 이미지의 텍셀을 읽을 때 각 채널을 어떻게 해석할 지에 대한 정보를 제공합니다. 이 정보는 대개 기본값을 사용합니다.subresourceRange: 이미지 뷰가 참조할 이미지의 범위를 나타내며, 어스펙트 마스크(aspect mask) 및 밉 레벨과 레이어 범위를 전달해야 합니다. 지금은 이미지가 컬러 이미지로써 작동하길 원하므로 어스펙트 마스크로vk::ImageAspectFlagBits::eColor를, 밉 레벨과 레이어 범위로 0부터 1까지를 전달합니다 (따라서 0번째 밉 레벨 및 0번째 레이어만을 참조합니다).
셰이더 작성하기
이미지와 이미지 뷰를 생성했으니, 이제 이 이미지의 각 텍셀을 어떻게 채울지를 규정하는 셰이더를 만들어봅시다. 이전 튜토리얼에서 셰이더의 각 invocation이 버퍼의 각 float에 대응했듯이, 이번에는 이미지의 각 텍셀에 대응하는 셰이더를 작성하겠습니다. 그러기 위해서는 워크 그룹 크기를 2차원으로 설정해야 하며, 따라서 16x16x1 워크 그룹 크기를 사용하겠습니다.
셰이더 코드를 multiply.comp에서 grid.comp로 바꾸고, 다음 코드를 작성합니다:
Subject: [PATCH] Modify compute shader to generate grid image.
---
Index: src/02_compute-image/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/CMakeLists.txt b/src/02_compute-image/CMakeLists.txt
--- a/src/02_compute-image/CMakeLists.txt
+++ b/src/02_compute-image/CMakeLists.txt
@@ -10,5 +10,5 @@
# --------------------
compile_shaders(02_compute-image
- shaders/multiply.comp
+ shaders/grid.comp
)
\ No newline at end of file
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -176,7 +176,7 @@
// Create compute shader module.
const vk::raii::ShaderModule computeShaderModule = [&] {
- const std::vector shaderCode = readFile("shaders/multiply.comp.spv");
+ const std::vector shaderCode = readFile("shaders/grid.comp.spv");
return vk::raii::ShaderModule { device, vk::ShaderModuleCreateInfo {
{},
shaderCode,
Index: src/02_compute-image/shaders/grid.comp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/shaders/grid.comp b/src/02_compute-image/shaders/grid.comp
new file mode 100644
--- /dev/null
+++ b/src/02_compute-image/shaders/grid.comp
@@ -0,0 +1,16 @@
+#version 450
+
+layout (set = 0, binding = 0, rgba8) writeonly uniform image2D outputImage;
+
+layout (local_size_x = 16, local_size_y = 16) in;
+
+void main(){
+ uvec2 outputImageSize = imageSize(outputImage);
+ vec4 color = vec4(
+ gl_LocalInvocationID.x == 0 || gl_LocalInvocationID.y == 0
+ ? vec2(0)
+ : vec2(gl_GlobalInvocationID.xy) / outputImageSize,
+ 0.0, 1.0);
+
+ imageStore(outputImage, ivec2(gl_GlobalInvocationID.xy), color);
+}
\ No newline at end of file
Index: src/02_compute-image/shaders/multiply.comp
===================================================================
diff --git a/src/02_compute-image/shaders/multiply.comp b/src/02_compute-image/shaders/multiply.comp
deleted file mode 100644
--- a/src/02_compute-image/shaders/multiply.comp
+++ /dev/null
@@ -1,10 +0,0 @@
-#version 450
-
-layout (set = 0, binding = 0) buffer Ssbo { float data[]; };
-
-layout (local_size_x = 256) in;
-
-void main(){
- uint index = gl_GlobalInvocationID.x;
- data[index] *= 2.0;
-}
\ No newline at end of file
디스크립터 셋 레이아웃을 설정하는 코드에 무언가 변화가 일어났고, main 함수 내 코드에도 못 보던 변수가 보입니다. 차근차근 이해해봅시다.
- 먼저
rgba8이라는 지정자(qualifier)가 추가되었습니다. 스토리지 이미지(storage image)를 셰이더에서 읽기 위해서는 이미지의 형식이 사전에 명시되어야 합니다2. 스토리지 버퍼가 컴퓨트 셰이더에서 읽고 쓸 수 있는 버퍼이듯, 스토리지 이미지 또한 읽고 쓸 수 있는 이미지를 의미합니다. writeonly uniform image2D지정자가 추가되었습니다.writeonly지정자는 이미지에 쓰기 연산만 적용된다는 뜻이며,uniform image2D는 디스크립터 타입이 2차원 이미지라는 뜻입니다. 스토리지 버퍼와 달리 스토리지 이미지에 대해서는 앞에uniform지정자가 붙습니다.main함수 내부imageSize함수는 디스크립터 이미지의 크기를 (너비, 높이)의 부호 없는 2차원 정수 벡터로 반환합니다.gl_LocalInvocationID는 지금 셰이더가 실행되는 invocation의 위치를 현재 워크그룹을 기준으로 한 인덱스로 반환합니다. 이젠 튜토리얼에서 사용했던gl_GlobalInvocationID와 달리, 이 값은 워크 그룹 내에서만 고유하며, 지금 워크그룹의 크기가 16x16x1이므로 이 값은 (0, 0, 0)부터 (15, 15, 0)까지의 격자값만을 가질 수 있습니다.imageStore함수는 이미지 디스크립터의 주어진 좌표 (ivec2(gl_GlobalInvocationID.xy))에 주어진 텍셀값을 저장합니다.
두 변수 gl_LocalInvocationID와 gl_GlobalInvocationID가 쓰였는데, 이 둘의 역할을 생각해보면 다음과 같은 결론을 얻을 수 있습니다:
gl_LocalInvocation.x == 0 || gl_LocalInvocation.y == 0은 현재 invocation이 워크 그룹의 맨 왼쪽 또는 맨 위쪽에 위치하는 경우 참입니다. 따라서 이 경우에는(0, 0, 0, 1)텍셀(검정)을 저장하고, 그 외에는 현재 invocation의 픽셀 위치(gl_GlobalInvocationID.xy)를 이미지의 크기로 나누어 텍셀 값의 R·G 범위가 ($[0, 1]^2$)에 있게 합니다. 따라서 이 컬러는 x좌표·y좌표가 변함에 따라 연속적으로 변하는 그래디언트가 생성됩니다.
이제 셰이더 코드가 준비됐으니, 마지막으로 디스크립터 관련 코드만 적절히 바꿔주면 됩니다. eStorageBuffer를 eStorageImage로 바꾸고, vk::DescriptorBufferInfo 구조체를 vk::DescriptorImageInfo 구조체로 바꾼 후 이미지 뷰와 현재 이미지의 레이아웃을 인수로 전달하면 됩니다 (이 구조체는 첫 번째 인수로 샘플러(sampler)를 전달해야 하나, 스토리지 이미지의 경우 샘플러를 전달할 필요가 없습니다).
Subject: [PATCH] Update descriptor related things.
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -158,7 +158,7 @@
const vk::raii::DescriptorSetLayout descriptorSetLayout = [&] {
constexpr vk::DescriptorSetLayoutBinding layoutBinding {
0,
- vk::DescriptorType::eStorageBuffer,
+ vk::DescriptorType::eStorageImage,
1,
vk::ShaderStageFlagBits::eCompute,
};
@@ -198,7 +198,7 @@
// Create descriptor pool.
const vk::raii::DescriptorPool descriptorPool = [&] {
constexpr vk::DescriptorPoolSize poolSize {
- vk::DescriptorType::eStorageBuffer,
+ vk::DescriptorType::eStorageImage,
1,
};
return vk::raii::DescriptorPool { device, vk::DescriptorPoolCreateInfo {
@@ -214,19 +214,18 @@
*descriptorSetLayout,
}).front();
- // Write buffer info to descriptorSet.
- const vk::DescriptorBufferInfo bufferInfo {
- *buffer,
- 0,
- vk::WholeSize,
+ // Write image info to descriptorSet.
+ const vk::DescriptorImageInfo imageInfo {
+ {},
+ *imageView,
+ vk::ImageLayout::eGeneral,
};
(*device).updateDescriptorSets(vk::WriteDescriptorSet {
descriptorSet,
0,
0,
- vk::DescriptorType::eStorageBuffer,
- {},
- bufferInfo,
+ vk::DescriptorType::eStorageImage,
+ imageInfo,
}, {});
// Create command pool.
vk::DescriptorImageInfo 구조체에 이미지 레이아웃으로 vk::ImageLayout::eGeneral이 전달됐습니다. 스토리지 이미지를 셰이더에서 사용하기 위해선 그 레이아웃이 GENERAL이어야 합니다. 음… 우리가 이미지 레이아웃을 설정했던 적이 있었나요? 무엇이든 명시적으로 해야 하는 Vulkan이기에 뭔가 미심쩍긴 하지만, 일단은 그렇게 넘어가겠습니다.
마지막으로 컴퓨트 셰이더의 워크 그룹 크기가 변경됐으므로, 컴퓨트 파이프라인의 디스패치 개수 또한 올바르게 바꿔주는 것을 잊지 마세요.
Subject: [PATCH] Update compute pipeline workgroup dispatch count.
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -245,7 +245,7 @@
commandBuffer.begin({ vk::CommandBufferUsageFlagBits::eOneTimeSubmit });
commandBuffer.bindPipeline(vk::PipelineBindPoint::eCompute, *computePipeline);
commandBuffer.bindDescriptorSets(vk::PipelineBindPoint::eCompute, *pipelineLayout, 0, descriptorSet, {});
- commandBuffer.dispatch(1024 / 256, 1, 1);
+ commandBuffer.dispatch(512 / 16, 512 / 16, 1);
commandBuffer.end();
// Submit commandBuffer to computeQueue and wait for it to finish.
코드를 변경하고 프로젝트가 성공적으로 빌드되는지 확인하세요. 아직은 컴퓨트 셰이더에서 이미지를 쓰는 작업만 했기 때문에 어떠한 출력물도 볼 수는 없겠지만, 적어도 무언가가 일어날 것이란 예감은 드는군요! 만약 성질이 급하다면, Renderdoc나 MoltenVK 환경일 경우 Metal debugger를 사용하여 생성된 이미지를 미리 볼 수도 있습니다. 두근거리는 마음을 안고 프로젝트를 실행해봅시다.
1
2
3
4
5
6
UNASSIGNED-CoreValidation-DrawState-InvalidImageLayout(ERROR / SPEC): msgNum: 1303270965 - Validation Error: [ UNASSIGNED-CoreValidation-DrawState-InvalidImageLayout ] Object 0: handle = 0x12ae0eb68, type = VK_OBJECT_TYPE_COMMAND_BUFFER; Object 1: handle = 0xfd5b260000000001, type = VK_OBJECT_TYPE_IMAGE; | MessageID = 0x4dae5635 | vkQueueSubmit(): pSubmits[0].pCommandBuffers[0] command buffer VkCommandBuffer 0x12ae0eb68[] expects VkImage 0xfd5b260000000001[] (subresource: aspectMask 0x1 array layer 0, mip level 0) to be in layout VK_IMAGE_LAYOUT_GENERAL--instead, current layout is VK_IMAGE_LAYOUT_UNDEFINED.
Objects: 2
[0] 0x12ae0eb68, type: 6, name: NULL
[1] 0xfd5b260000000001, type: 10, name: NULL
Process finished with exit code 0
역시 아까 전 두루뭉실하게 넘어간 이미지 레이아웃 관련 검증 오류가 발생합니다. 오류를 읽어보면, 이미지의 0번째 레이어·0번째 밉 레벨의 레이아웃이 VK_IMAGE_LAYOUT_GENERAL일 것으로 예측됐으나, 실제로는 VK_IMAGE_LAYOUT_UNDEFINED였다고 합니다. vk::DescriptorImageInfo에서 이미지 레이아웃을 eGeneral로 명시했으나, 실제 이미지 레이아웃은 eUndefined이기 때문입니다. 모든 이미지는 처음 생성할 때 eUndefined로 초기화됩니다.
그렇다면, 어떻게 이미지 레이아웃을 eGeneral로 변경할 수 있을까요? 이를 수행하는 방법은 바로 Vulkan의 꽃인 파이프라인 배리어(pipeline barrier)를 이용하는 것입니다. 이 파이프라인 배리어는 Vulkan을 비동기적으로 만들어주는 핵심 요소이자, 동기화에 관련한 난해한 개념입니다. 다음 튜토리얼에서는 어떻게 파이프라인 배리어를 구성해야 하는지에 대해 알아보겠습니다.
이번 튜토리얼의 전체 코드 변경 사항은 다음과 같습니다.
Subject: [PATCH] Update compute pipeline workgroup dispatch count.
Update descriptor related things.
Modify compute shader to generate grid image.
Create image view for image[mipLevel=0, arrayLayer=0].
Create image that to be processed by compute shader.
Move getMemoryTypeIndex function right below to the physical device declaration (this function is depend on physical device property)
---
Index: src/02_compute-image/main.cpp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/main.cpp b/src/02_compute-image/main.cpp
--- a/src/02_compute-image/main.cpp
+++ b/src/02_compute-image/main.cpp
@@ -80,6 +80,19 @@
const vk::raii::PhysicalDevice physicalDevice = instance.enumeratePhysicalDevices().front();
+ const auto getMemoryTypeIndex
+ = [memoryTypes = physicalDevice.getMemoryProperties().memoryTypes](
+ vk::MemoryPropertyFlags memoryPropertyFlags
+ ) -> std::uint32_t {
+ for (auto [idx, memoryType] : memoryTypes | std::views::enumerate) {
+ if ((memoryType.propertyFlags & memoryPropertyFlags) == memoryPropertyFlags) {
+ return idx;
+ }
+ }
+
+ throw std::runtime_error { "No suitable memory type found." };
+ };
+
const std::uint32_t computeQueueFamilyIndex = [&] {
for (auto [idx, properties] : physicalDevice.getQueueFamilyProperties() | std::views::enumerate) {
if (properties.queueFlags & vk::QueueFlagBits::eCompute) {
@@ -113,43 +126,39 @@
const vk::Queue computeQueue = (*device).getQueue(computeQueueFamilyIndex, 0);
- const vk::raii::Buffer buffer { device, vk::BufferCreateInfo {
+ // Create image that to be processed by compute shader.
+ const vk::raii::Image image { device, vk::ImageCreateInfo {
{},
- sizeof(float) * 1024,
- vk::BufferUsageFlagBits::eStorageBuffer,
+ vk::ImageType::e2D,
+ vk::Format::eR8G8B8A8Unorm,
+ { 512, 512, 1 },
+ 1, 1,
+ vk::SampleCountFlagBits::e1,
+ vk::ImageTiling::eOptimal,
+ vk::ImageUsageFlagBits::eStorage,
} };
- const auto getMemoryTypeIndex
- = [memoryTypes = physicalDevice.getMemoryProperties().memoryTypes](
- vk::MemoryPropertyFlags memoryPropertyFlags
- ) -> std::uint32_t {
- for (auto [idx, memoryType] : memoryTypes | std::views::enumerate) {
- if ((memoryType.propertyFlags & memoryPropertyFlags) == memoryPropertyFlags) {
- return idx;
- }
- }
-
- throw std::runtime_error { "No suitable memory type found." };
- };
-
- const vk::raii::DeviceMemory bufferMemory { device, vk::MemoryAllocateInfo {
- buffer.getMemoryRequirements().size,
- getMemoryTypeIndex(vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent),
+ const vk::raii::DeviceMemory imageMemory { device, vk::MemoryAllocateInfo {
+ image.getMemoryRequirements().size,
+ getMemoryTypeIndex(vk::MemoryPropertyFlagBits::eDeviceLocal),
} };
- buffer.bindMemory(*bufferMemory, 0);
-
- // Map whole ranges of bufferMemory into host memory.
- void* const data = (*device).mapMemory(*bufferMemory, 0, vk::WholeSize);
+ image.bindMemory(*imageMemory, 0);
- // Fill buffer with floats from 0 to 1023.
- const std::span nums { static_cast<float*>(data), 1024 };
- std::iota(nums.begin(), nums.end(), 0.f);
+ // Create image view for image[mipLevel=0, arrayLayer=0].
+ const vk::raii::ImageView imageView { device, vk::ImageViewCreateInfo {
+ {},
+ *image,
+ vk::ImageViewType::e2D,
+ vk::Format::eR8G8B8A8Unorm,
+ {},
+ vk::ImageSubresourceRange { vk::ImageAspectFlagBits::eColor, 0, 1, 0, 1 },
+ } };
// Create descriptor set layout.
const vk::raii::DescriptorSetLayout descriptorSetLayout = [&] {
constexpr vk::DescriptorSetLayoutBinding layoutBinding {
0,
- vk::DescriptorType::eStorageBuffer,
+ vk::DescriptorType::eStorageImage,
1,
vk::ShaderStageFlagBits::eCompute,
};
@@ -167,7 +176,7 @@
// Create compute shader module.
const vk::raii::ShaderModule computeShaderModule = [&] {
- const std::vector shaderCode = readFile("shaders/multiply.comp.spv");
+ const std::vector shaderCode = readFile("shaders/grid.comp.spv");
return vk::raii::ShaderModule { device, vk::ShaderModuleCreateInfo {
{},
shaderCode,
@@ -189,7 +198,7 @@
// Create descriptor pool.
const vk::raii::DescriptorPool descriptorPool = [&] {
constexpr vk::DescriptorPoolSize poolSize {
- vk::DescriptorType::eStorageBuffer,
+ vk::DescriptorType::eStorageImage,
1,
};
return vk::raii::DescriptorPool { device, vk::DescriptorPoolCreateInfo {
@@ -205,19 +214,18 @@
*descriptorSetLayout,
}).front();
- // Write buffer info to descriptorSet.
- const vk::DescriptorBufferInfo bufferInfo {
- *buffer,
- 0,
- vk::WholeSize,
+ // Write image info to descriptorSet.
+ const vk::DescriptorImageInfo imageInfo {
+ {},
+ *imageView,
+ vk::ImageLayout::eGeneral,
};
(*device).updateDescriptorSets(vk::WriteDescriptorSet {
descriptorSet,
0,
0,
- vk::DescriptorType::eStorageBuffer,
- {},
- bufferInfo,
+ vk::DescriptorType::eStorageImage,
+ imageInfo,
}, {});
// Create command pool.
@@ -237,7 +245,7 @@
commandBuffer.begin({ vk::CommandBufferUsageFlagBits::eOneTimeSubmit });
commandBuffer.bindPipeline(vk::PipelineBindPoint::eCompute, *computePipeline);
commandBuffer.bindDescriptorSets(vk::PipelineBindPoint::eCompute, *pipelineLayout, 0, descriptorSet, {});
- commandBuffer.dispatch(1024 / 256, 1, 1);
+ commandBuffer.dispatch(512 / 16, 512 / 16, 1);
commandBuffer.end();
// Submit commandBuffer to computeQueue and wait for it to finish.
@@ -247,10 +255,4 @@
commandBuffer,
});
computeQueue.waitIdle();
-
- // Check if the result is correct.
- constexpr auto expected = std::views::iota(0, 1024) | std::views::transform([](float x) { return x * 2.f; });
- assert(std::ranges::equal(nums, expected) && "Unexpected result.");
-
- (*device).unmapMemory(*bufferMemory);
}
\ No newline at end of file
Index: src/02_compute-image/CMakeLists.txt
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/CMakeLists.txt b/src/02_compute-image/CMakeLists.txt
--- a/src/02_compute-image/CMakeLists.txt
+++ b/src/02_compute-image/CMakeLists.txt
@@ -10,5 +10,5 @@
# --------------------
compile_shaders(02_compute-image
- shaders/multiply.comp
+ shaders/grid.comp
)
\ No newline at end of file
Index: src/02_compute-image/shaders/grid.comp
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/02_compute-image/shaders/grid.comp b/src/02_compute-image/shaders/grid.comp
new file mode 100644
--- /dev/null
+++ b/src/02_compute-image/shaders/grid.comp
@@ -0,0 +1,16 @@
+#version 450
+
+layout (set = 0, binding = 0, rgba8) writeonly uniform image2D outputImage;
+
+layout (local_size_x = 16, local_size_y = 16) in;
+
+void main(){
+ uvec2 outputImageSize = imageSize(outputImage);
+ vec4 color = vec4(
+ gl_LocalInvocationID.x == 0 || gl_LocalInvocationID.y == 0
+ ? vec2(0)
+ : vec2(gl_GlobalInvocationID.xy) / outputImageSize,
+ 0.0, 1.0);
+
+ imageStore(outputImage, ivec2(gl_GlobalInvocationID.xy), color);
+}
\ No newline at end of file
Index: src/02_compute-image/shaders/multiply.comp
===================================================================
diff --git a/src/02_compute-image/shaders/multiply.comp b/src/02_compute-image/shaders/multiply.comp
deleted file mode 100644
--- a/src/02_compute-image/shaders/multiply.comp
+++ /dev/null
@@ -1,10 +0,0 @@
-#version 450
-
-layout (set = 0, binding = 0) buffer Ssbo { float data[]; };
-
-layout (local_size_x = 256) in;
-
-void main(){
- uint index = gl_GlobalInvocationID.x;
- data[index] *= 2.0;
-}
\ No newline at end of file